

Internet poco a poco va haciéndose más y más grande. A medida que crecen sus usuarios y dispositivos conectados lo hacen las necesidades de los mismos, y de los servicios que ofrece. Hoy vamos a meternos con los WebSockets. Este sistema se utiliza para hacer una comunicación bidireccional y persistente entre un cliente y un servidor web. Pero, ¿para qué queremos esto?
Tabla de contenidos
Un poco de background
Para realizar una comunicación entre un cliente web (navegador) y un servidor web (cualquier programa que sea capaz de enviar información coherente a un navegador) se utiliza el protocolo HTTP (por debajo utiliza TCP/IP y muchas más cosas, pero no profundizaremos tanto). Este protocolo define la forma en la que un navegador tiene que pedir una web a un servidor. Como literatura, podemos leernos el RFC 2616 que, aunque no es el más actualizado nos cuenta muchas cosas útiles acerca de cómo funciona HTTP/1.1.
Básicamente lo que hace un cliente cada vez que quiere una web es conectarse a un servidor, pedir dicha web y esperar a que el servidor se la devuelva. Y, tanto el cliente como el servidor se olvidan de que esta relación ha existido, se cierra la conexión y si te he visto no me acuerdo; es decir, cada vez que vas a pedir algo, tienes que saludar al servidor, decirle qué quieres, cómo lo quieres, presentarte y despedirte, y el servidor no se acordará de ti cuando le pidas algo de nuevo. En realidad no es 100% así, como ya veremos más adelante.
El caso es que es una conexión de una sola petición, efímera, y eso está bien, porque el protocolo está diseñado para atender a mucha gente, y no podemos estar manteniendo vivas conexiones de forma gratuita. De esta forma, cuando se cierra una conexión se puede atender a otra persona que esté pidiendo algo al mismo servidor. El problema es que establecer una conexión es muy lento, depende de tu conexión, pero 250-500ms; eso sí, cuando para ver una web tienes que descargar un HTML, 10 archivos Javascript, 5 archivos CSS, 6 archivos de tipografía y 25 imágenes, tenemos que crear muchas conexiones (una por cada petición 47 conexiones, que se dice pronto). Para esto se utilizan tecnologías como KeepAlive, que provoca que el servidor, una vez haya entregado una web no cierre la conexión, sino que espere unos segundos antes de esto, así si el navegador tiene que pedir algo más, lo pedirá desde la misma conexión abierta y nos ahorraremos unos milisegundos de procesado (que claro, multiplicados, pueden ser varios segundos de ganancia). Además, las peticiones se suelen hacer en paralelo, es decir, se establecen varias conexiones con el servidor (entre 2 y 8), y si el servidor puede, lo sirve todo al mismo tiempo (las imágenes, CSS, Javascripts, tipos de letra, etc normalmente no requieren que el servidor ejecute nada y sólo implican leer un archivo y servirlo).

Y ahora, cuando estoy logeado en una web, ¿cómo recuerda éste quién soy cada vez que hago una petición a la web? Lo hablaremos en otro post, que este tema me gusta.
Ahora bien, estamos en un mundo web dinámico, las webs no son ya entes estáticos que se sirven, sino que tienen sistemas de usuarios, almacenan datos, comparten datos entre usuarios, envían mensajes, y muchas de ellas, mientras estás viendo una página son capaces de mostrarte información nueva como mensajes o notificaciones, valores de bolsa en tiempo real, juegos multijugador en los que varias personas realizan acciones al mismo tiempo y el resto de los jugadores debe verlo (o sufrirlo), o incluso sistemas colaborativos de creación, edición de documentos o gestión de bases de datos. Esto podemos verlo, por ejemplo cuando sucede algo que requiere tu atención, te aparece una notificación al instante, o cuando te mandan un mensaje de chat. Hace muchos años, para esto se utilizaba un Applet Java, pero estos applets suelen ser peligrosos, no suelen funcionar en todos los navegadores, o con todas las versiones de Java, incluso muchas personas evitan que Java se ejecute en su navegador, y cuando el programa tiene unos años, puede que versiones futuras de Java sean incapaces de correrlo. Y otra cosa más, normalmente estos sistemas en Java, creaban conexiones persistentes a puertos no estándar, con protocolos diseñados para funcionar con ese programa y necesitaban de un servidor especial corriendo, por lo que, por un lado, muchos proxys rechazaban esas conexiones, muchos servicios de Internet públicos (universidades, cibercafés, etc) también las rechazaban, la seguridad no se tomaba muy en serio porque ya era duro diseñar un protocolo nuevo para la web, ¡como para hacerlo seguro encima! Y por si fuera poco actualizar y mantener dicho software era costoso y en definitiva caro. Por lo que, aunque tuvo su época y su auge en el pasado, ya no se usa. He puesto un ejemplo un poco exagerado, aunque era típico ver chats en Java que conectaba con un servidor IRC (al menos es un protocolo estándar), pero claro, teníamos problema con proxys o con salas públicas, y cuando se han ido actulaizando versiones de Java, de los navegadores, etc han dejado de funcionar.
Bueno, avanzamos unos años y entramos en el mundo Ajax. Ahora, desde Javascript lanzamos peticiones HTTP, y nos permiten cargar partes de una página a medida que navegamos, enviar información a un servidor sin tener que salir de una página y recargarlo todo, y por ejemplo, estos sistemas en los que nos tenemos que comunicar en tiempo real con el servidor (recibir notificaciones o enviar mensajes de forma instantánea) son más sencillos. Sólo añadiendo algo de Javascript podemos comunicarnos con el servidor. Eso sí, tendremos que crear una conexión nueva y enviar la información, pero como el usuario está visitando una web, la página no tiene que recargar y le podemos poner una pequeña animación, no se impacienta tanto. Además, si queremos implementar un chat, podríamos programar una petición al servidor cada segundo, por ejemplo, sería una cosa sencilla, como si el navegador preguntara: ¿hay algo para mí? y el servidor si hay algo, lo manda y si no, dice que no y listo. Nos quitamos Java del tirón, conexiones persistentes a puertos extraños, problemas de compatibilidad en el futuro, problemas con los proxys y algo más. Si nos lo montamos bien será un sistema robusto aunque, generará mucha transferencia de datos (nada más que estableciendo conexiones y mandando peticiones, algo más de 1Kb podemos transmitir, serían unos 3Mb a la hora, pero si tenemos 1000 usuarios, ya son 3Gb por hora, además no es tiempo real tiempo real, como mucho el retraso será de un segundo (si las conexiones se realizan bien a la primera)… y bueno, muchas veces la protección de los servidores contra denegación de servicio puede saltar la alarma al tratarse de la creación de muchas conexiones.
Pidiendo HTTP a mano
Vamos a hacer una conexión HTTP a mano, es decir, nos vamos a conectar al puerto 80 de una web y le vamos a pedir algo, y luego esperamos que nos responda. Tenemos que tener en cuenta el código CRLF, esto significa retorno de carro y nueva línea (es como las máquinas de escribir, le das a la palanca que está a la derecha, entonces mueves el carro al principio y saltas de línea, para seguir escribiendo en la línea siguiente. En algunos lenguajes podemos representar estos símbolos como \r\n y son los bytes (0x0d y 0x0a, en decimal 13 10), aunque si lo hacemos desde consola, podremos darle a Enter y listo. Por ejemplo, si queremos pedir http://google.com/ desde nuestro terminal podemos utilizar telnet de la siguiente forma:
Bueno, Google nos responde con una redirección. Lo que hemos hecho ha sido hacer una solicitud al servidor google.com al puerto 80 (línea de telnet), y luego hacemos una petición GET / HTTP/1.1 (es decir, tráeme lo que tienes en el directorio raíz http://google.com/ eso sí, hablamos protocolo HTTP versión 1.1 (CRLF), luego le decimos el Host que queremos traernos (porque aunque google.com corresponde con una IP, 216.58.214.174 en mi caso, dentro de la misma IP podría haber más dominios), y luego dos CRLF (con dos CRLF indicamos el final de nuestra petición y le damos la vez al servidor) que nos responderá un código 302 Found, nos hablará del caché, del contenido que nos envía y el juego de caracteres (Content-Type: text/html; charset=UTf-8), del tamaño de la respuesta (Content-Length: 256), de la fecha de generación de la misma y podrá decirnos muchas más cosas.
Antes comenté que la petición podría ser de 1Kb, y es que nosotros también podemos enviar mucha información además del Host:
- Accept-Encoding: Indica el método de compresión que nuestro cliente web soporta (el servidor nos puede enviar la página descomprimida, pero sólo si el navegador sabe cómo descomprimirla). Podemos separar los métodos por comas ordenándolos por nuestra preferencia. Por ejemplo deflate, gz, br, sdch
- Accept-Language: Indica el idioma del usuario. Así una web puede detectar el idioma del visitante y darle contenidos que pueda leer. Por ejemplo: es-ES,es (español de España, o español, daría igual el país).
- User-Agent: Indica el navegador, versiones, sistema operativo, etc, para que el servidor sepa quién realiza la petición.
- Accept: Indica qué tipos de contenido acepta el navegador.
- Referer: Indica de qué página vienes.
- Connection: Indica qué tipo de conexión soporta el cliente. Por ejemplo Connection: keep-alive indica que el navegador soporta esta tecnología, y el servidor podrá utilizarla si quiere.
También podremos enviar códigos de autorización, cookies, condicionales y muchas más cosas de las que hablaré en futuros posts. Por ejemplo, la conexión con Google podría quedar:
Ahora la petición es más compleja, he conectado con www.google.es (porque cuando pedí a google.com me hizo una redirección a www.google.es), además, la ruta no es / sino que es un poco más larga. También le he pedido que comprima los datos con gzip o deflate, le he dicho cómo se llama mi navegador, desde la página que he accedido y que si quiere mantener la conexión abierta que lo haga.
Google me respondió con un OK, me dirá la fecha, la caducidad, cómo me ha comprimido los datos, cómo se llama su servidor (gws – Google Web Server), cuánto tamaño tiene la web que me manda, una cookie y algunas cosas más. El contenido marcado como xxxyyyzzz son datos comprimidos con gzip que, si nos apetece podemos guardarlos en un fichero, ejecutar gunzip junto con ese archivo y abrir los contenidos para verlos en texto plano.
Eso sí, todo esto se hace muchas veces, muy rápido y esa es la comunicación vía web.
WebSockets
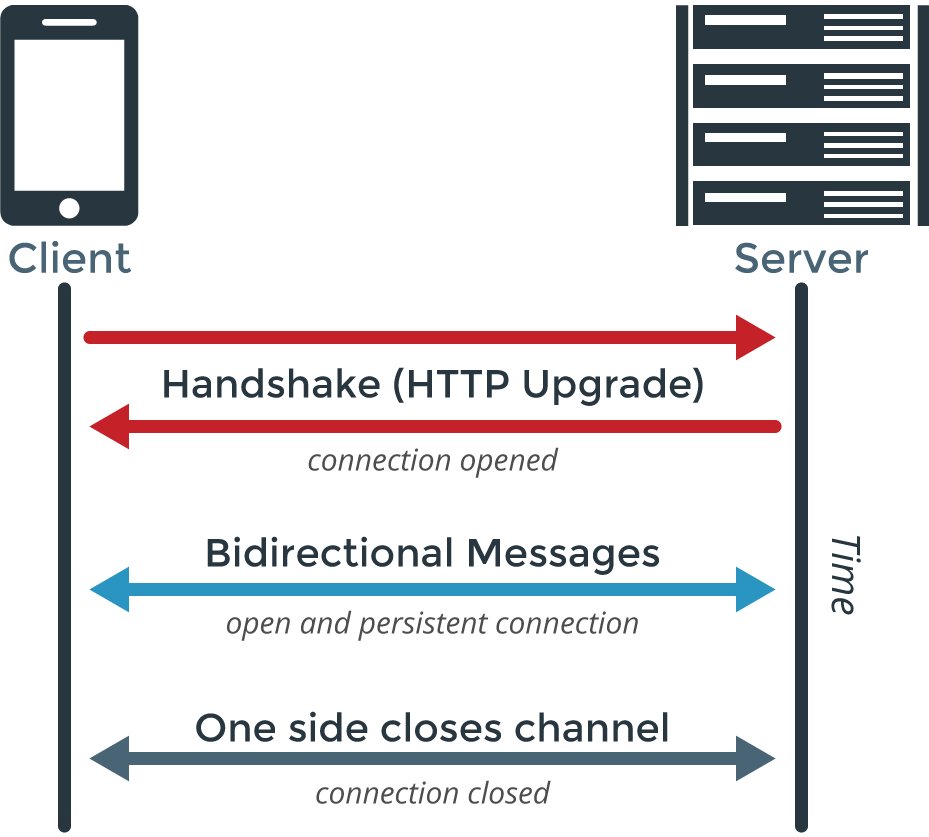
Desde hace unos años (el estándar salió en el 2011), podemos utilizar la tecnología WebSocket. Bueno, esto viene de Socket, que significa enchufe y es el sistema que se utiliza para conexión de red, y Web (donde nos referimos a HTTP más que a una telaraña). El objetivo es crear conexiones bidireccionales y persistentes entre un cliente y un servidor. De esta forma, cuando creamos la conexión, cliente y servidor hacen una negociación de cómo comunicarse, utilizando el mismo esquema que HTTP en la que deciden mantener abierto el puerto y empezar a enviarse mensajes en tiempo real.
De esta forma, un servidor podrá enviar a un cliente cualquier mensaje en cualquier momento y el cliente lo recibiría al instante, y lo mismo en sentido contrario: un mensaje que generemos en el navegador podrá ser enviado sin necesidad de establecer una nueva conexión porque ya hay abierta una. Por otro lado, al estar basado en HTTP, es fácil implementar una capa de seguridad (utilizando HTTPS), no estaríamos utilizando puertos raros (aunque podemos, pero podemos utilizar el mismo puerto 80), no estaríamos enviando demasiada información ya que la negociación y petición se hace sólo una vez al principio (y como mucho cuando haya una desconexión y reconexión, que puede ser cada varios minutos, si ésta se produce). El único problema, serían los proxys, hay proxys que no entienden este tipo de conexiones y las rechazan, pero bueno, habría que darles tiempo; bueno, también tendríamos problema de sobrecarga cuando hay muchos clientes, pero eso deberíamos resolverlo internamente (más hardware para soportar más gente conectada, ir desconectando a los inactivos…)
Los WebSockets son un poco más complejos, la base de la comunicación es HTTP, aunque va a ser un poco complicado hacer una comunicación WebSocket desde telnet ya que hay que introducir códigos binarios y hacer cuentas. Si queréis lectura de baño, os remito a RFC 6455.
Básicamente lo que debemos hacer como clientes (navegadores) es una negociación de protocolo, diciendo que, usamos HTTP/1.1 pero queremos que esa conexión se transforme en WebSocket, de la siguiente manera:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: RQbGiM4lvNU0zredy6VuUQ==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com
Es decir, hacemos una petición HTTP a la ruta donde está nuestro WebSocket (/chat) y le decimos (Connection: upgrade y Upgrade: websocket), es decir, quiero actualizar la conexión como una WebSocket, además, indico la versión (13 por el momento) y una clave (Sec-WebSocket-Key) que será una ristra de bytes aleatorios en base64, más que nada para que un intermediario que haya cacheado las peticiones nos envíe datos de una sesión anterior. Aunque también actúa como un paso más de handshake verificando que el servidor es legítimo. Es más, incluso cuando vamos a hacer una conexión WebSocket, en lugar de utilizar http:// o https:// utilizamos ws:// o wss:// aunque esto sólo indica el tratamiento que hacemos con la conexión, porque como vemos, hablamos un idioma HTTP.
Una vez que el cliente envía esto, se recibe algo como:
Access-Control-Allow-Headers: x-websocket-version
Access-Control-Allow-Origin: server.example.com
Connection: Upgrade
Date: Sun, 04 Sep 2016 20:13:40 GMT
Sec-WebSocket-Accept: rFff6EsE9BN9mQfYB/TD55FL0yg=
Server: Mi-servidor-molon
Upgrade: websocket
O lo que es lo mismo, que voy a hacer caso a xxx-WebSocket-Version (el cliente puede pedir extensiones, compresión y mil cosas más), aceptamos el upgrade de la conexión y devolvemos una clave en Sec-WebSocket-Accept. Esta clave será el resultado de coger la Sec-WebSocket-Key que manda el cliente, y juntarla con un GUID mágico: 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 (tal cual, como string), a eso le aplicamos un SHA-1 y luego un base64. Por ejemplo, en bash podemos hacer:
1 2 | SEC="RQbGiM4lvNU0zredy6VuUQ==" echo -n $SEC"258EAFA5-E914-47DA-95CA-C5AB0DC85B11" | openssl sha1 -binary | base64 |
Muy importante el -n de echo (para que no meta caracteres de fin de línea que nos puedan modificar totalmente el SHA1 y el -binary, ya que si no, openssl codificará el hash en hexadecimal y tampoco nos conviene.
El caso es que en este punto ya tenemos nuestra conexión persistente y full-duplex, es decir, cualquiera de las partes, cliente o servidor, podrá comunicarse con la otra cuando quiera, sin tener que esperar turnos, ni hacer nada especial, sólo enviar un mensaje.
Eso sí, los mensajes que intercambiarán cliente y servidor se llamarán Frames, y tendrán una estructura especial.
WebSocket Frames
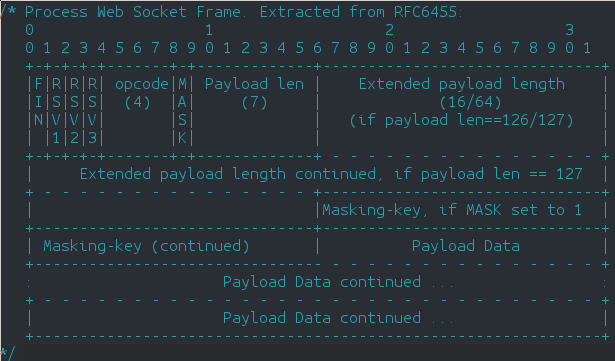
Cada frame tendrá un conjunto de bytes que vamos a diseccionar aquí (aunque presentaremos algún caso sencillo). Es más, este formato de frame, vale tanto para cliente como servidor, aunque no siempre se podrá enviar cualquier tipo de Frame desde uno o desde otro, ya veremos cómo va. El esquema general es el siguiente:
 .
.
En este esquema vemos los bytes que tiene que tener nuestro frame, ya que tenemos que introducir y presentar la información de determinada forma para que la comunicación sea fluida.
Lo primero es especificar los tipos de frame que podemos enviar, que pueden ser de datos (primer bit a 0) o de control (primer bit a 1). Los de datos enviarán información de nuestra aplicación (mensajes, notificaciones, movimientos, etc) y los de control manejan el protocolo, por ejemplo envían señales para mantener viva la conexión, para verificar que un cliente o un servidor está activo, o cierran la conexión (siempre puedes tirar del cable, pero está bien cerrar la conexión de forma pacífica, como desconectar un USB de forma segura).
Los tipos son los siguiente:
- Continuación (0 decimal = 0x0 = 0000 binario) : Indica que el frame es una continuación de un frame anterior).
- Text (1 decimal = 0x1 = 0001 binario) : Indica que el frame envía datos en formato texto.
- Binario (2 decimal = 0x2 = 0010 binario) : Indica que el frame envía datos binarios.
- Close (8 decimal = 0x8 = 1000 binario) : Indica que esta parte quiere cerrar la conexión. Podemos incluir como datos el motivo por el que cerramos la conexión. Y debe ser contestado por la otra parte con un Close.
- Ping (9 decimal = 0x9 = 1001 binario) : Envía un ping para verificar si la otra parte está viva. Debe ser contestado cuanto antes con un Pong.
- Pong (10 decimmal = 0xa = 1010 binario): Envía un pong como respuesta de un ping. ¿Qué pasa si recibimos un Pong sin esperarlo? Nosotros decidimos, podemos cerrar el programa diciendo que ha habido un error, o podemos hacer como si no pasara nada, aunque no sabemos si nos mandarán más cosas mal.
El primer byte especificará el tipo de frame y alguna cosa más. El byte FIN indicará si se trata del último frame de una secuencia, por lo que si es un frame único, pondremos un 1. RSV1, RSV2 y RSV3 dependerán de extensiones del protocolo y casos específicos de aplicaciones, por lo que podemos poner 3 ceros aquí, y el opcode que serán 4 bytes será un código que indicará el tipo de frame con su código. En nuestro programa debemos generar un byte completo con toda esta información.
En el segundo byte se especificará como primer bit si el dato vendrá enmascarado (tendrá un cifrado XOR, en principio pondremos un 0, para simplificar, es más, un servidor jamás podrá enmascarar) y los otros 7 bits restantes indicarán el tamaño del paquete, pero claro, 7bits es muy poco, así que si el tamaño es de 125bytes, pondremos 125, que entra perfectamente, si es desde 126 a 65535 bytes pondremos 126 y si es más grande, pondremos 127 con lo que tendremos capacidad para frames realmente enormes.
En caso de que el tamaño sea 126, tendremos 2bytes adicionales para especificar el tamaño y si es 127, tendremos 8bytes (podemos poner números muy grandes con 8bytes).
A continuación, si el bit MASK está a 1 (aunque en el ejemplo será 0) tendremos 4 bytes para especificar una máscara, que podrán ser bytes aleatorios.
Lo siguiente será especificar los datos, que no podrán exceder el tamaño especificado. Por tanto, si queremos enviar un paquete que diga HOLA, este debe tener la siguiente forma:
10000001 (bit FIN y opcode 0x01, o texto)
00000100 (bit MASK a 0, y tamaño = 4)
HOLA (ya podemos poner los bytes de forma normal)
Como dije antes, sólo si somos clientes podemos enmascarar los mensajes, sólo por introducir algo de cifrado simple y complicar un poco la cosa. Es algo más simple, un XOR con 4 bytes de máscara, ya que si volvemos aplicar el XOR al texto codificado nos vuelve a salir el texto original.
Programando
Es cierto que la mayoría de personas escogen utilizar una biblioteca (o librería) cuando quieren hacer este tipo de cosas. Normalmente estará mucho más probada que cualquier proyecto que hagamos nosotros desde cero. Además, tendrá más opciones y podremos utilizarlas sin quebrarnos la cabeza. Esto forma parte de un proyecto personal que empezó siendo una investigación sobre este tipo de protocolos y ha crecido un poco.
Personalmente, me gusta conocer las tripas de cualquier sistema. De hecho, en muchas ocasiones suele ser muy útil cuando una biblioteca falla o cuando un sistema no hace lo que se espera de él y quería resumir un poco esas investigaciones aquí, de forma agnóstica al lenguaje de programación, aunque pronto me meteré con código, que es lo que más me gusta.
Tras la chapa…
Después de toda esta chapa sobre HTTP y WebSockets, la semana que viene veremos un ejemplo de implementación en C++ y la posibilidad de crear nuestro sistema de Chat en este lenguaje con pocas líneas de código (yo te proporciono la biblioteca). Además veremos configuraciones con Apache y algo de seguridad.
Foto principal: Andrew Phillips






Pingback: ¿Cómo funcionan los WebSockets? Comunicación bidireccional en tiempo real con el navegador web | PlanetaLibre /
Exelente post!, bien detallado,
Espero con muchas ansias tu post del ejemplo! 🙂
Pienso implementar esto con un programa en lua, para crear un chat simple con un amigo! 🙂
¡¡ Muchas gracias Davis !! Te voy dando un pequeño adelanto: https://github.com/gasparfm/glove aquí hay un ejemplo llamado glovewschat en el que me baso para el siguiente post. Y si te animas a compartir por aquí tu programa en lua estaré encantado de mostrarlo en un post 🙂
Pingback: ¿Cómo crear un chat utilizando WebSockets en C++? Y no morir en el intento – Poesía Binaria /
Muy bueno tu post buscaba algo asi para conocer mejor la relacion entre WebSocket y HTTP. Felicidades por el conocimento alcanzado y MUCHAS GRACIAS por compartilo
Detroit website design agency
Excelente; su artículo estaba buscando algo en este sentido para aclarar la conexión entre HTTP y WebSocket. Enhorabuena por adquirir la baldi’s basics información, y un sincero agradecimiento por compartirla.
Thanks for sharing informative post. It is one of the best site that I have visited. Hope you will share more quality blog posts thank you.
Vintage Scarface Jacket
It took me some time to read all of the comments, but I found the article to be quite intriguing. It was quite helpful to me, and I’m sure to everyone else here as well driving directions mapquest!
Extraordinary literary skills are demonstrated in the ordinary, which can be said to be a gem in every word. Many of the viewpoints in the post have benefited me greatly, you are really great! 메이저사이트
I think they’re having a great time reading this post, and they might take a good site to find out more io games free