

Algo que nos puede traer de cabeza como administradores de sistemas y, a veces como usuarios es el hecho de que un proceso se coma, devore y trate sin piedad la CPU de nuestro sistema. Ya no solo el hecho de que un programa deje inservible el ordenador, aunque a día de hoy con tantos núcleos de procesador, casi siempre tendremos algo de CPU para enviar una señal de parada a un proceso. Un ejemplo más claro puede que tengamos dos programas en ejecución (o más), uno de ellos nos corre más prisa que el otro, ¡pero el ordenador no lo sabe! Así que, si utilizan la CPU de forma intensiva terminarán utilizando el 50% de la CPU cada uno.
Pero claro, un proceso necesitamos que esté listo antes, lo lógico es asignarle más CPU a éste. ¿Qué opciones tenemos?
Tabla de contenidos
La medida obvia, ejecución secuencial
Lo primero que se nos pasa por la cabeza es ejecutar primero el proceso que nos corre prisa, y cuando termine ejecutar el otro. Esto puede ser una buena solución en muchas ocasiones. Pero claro, ¿y si los procesos llevan lanzados ya un tiempo y han avanzado en su progreso? detener uno de ellos puede suponer la pérdida del estado que se ha conseguido. Puede que nos compense, o puede que no.
¿Y si estamos hablando de programas demonio? Los programas están en ejecución en segundo plano, haya momentos de gran utilización de CPU y momentos en los que no se usa, pero sí sabemos que uno tiene preferencia sobre otro. O al menos no queremos dejar sin CPU a los demás programas en ejecución.
Señales (peleando con la terminal)
Lo siguiente que se nos puede ocurrir es pausar y reanudar procesos. Si tenemos los procesos en dos terminales por separado, podemos pulsar Control+Z en el que deseemos pausar y luego escribir fg para reanudarlo. No tiene pérdida. Pero si los procesos no tienen un terminal, también podemos hacerlo enviándoles las señales SIGSTOP y SIGCONT. Para poner un ejemplo, he creado un pequeño script en Bash (muy tonto y lo he llamado consumidor.sh):
1 2 3 | #!/bin/bash while (( 1 )); do echo CONSUMO CPU; done |
Ahora lo ejecuto y me olvido de esa terminal porque no puedo tocarla. Desde otra terminal ejecuto top.
En lugar de consumidor.sh podríamos utilizar la siguiente línea:
Que se pondrá a calcular con un solo núcleo 100000 dígitos del número Pi.
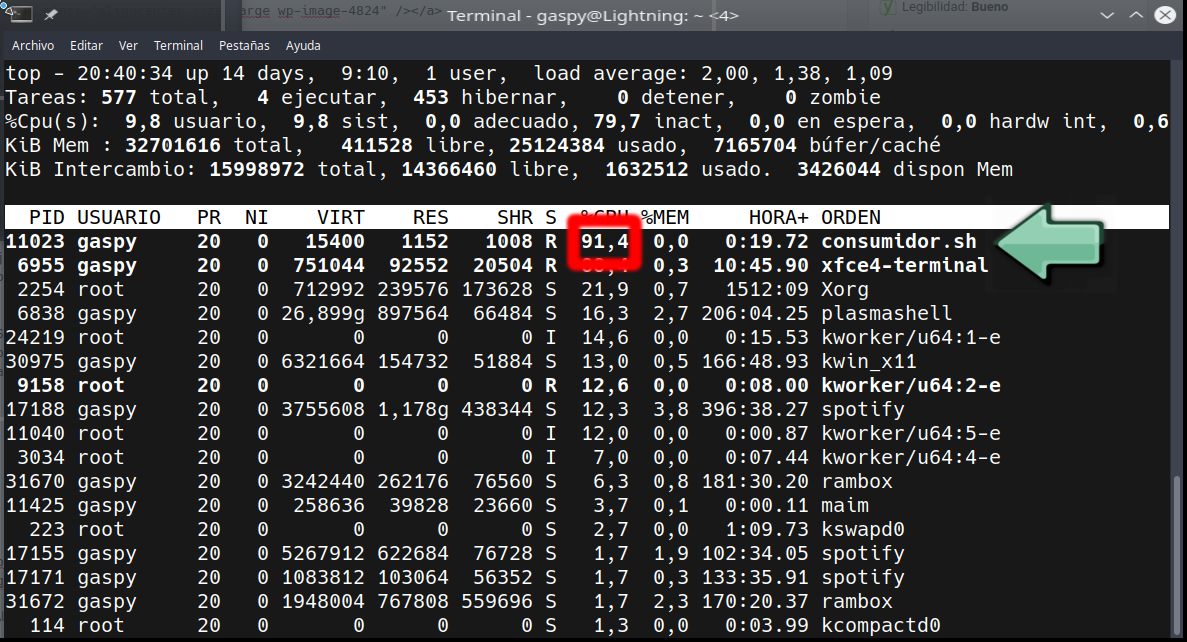
Como vemos, tenemos un proceso consumidor.sh que está tirando bastante de CPU, así que, conociendo el PID (process ID o identificador de proceso) podemos ejecutar:
En ese momento vemos que ya no es un proceso que consuma CPU. Sigue en ejecución, pero está en pausa. Que no os asuste el comando kill, que no estamos matando a nadie, aún, sólo le decimos al sistema operativo que no le de más CPU hasta nueva orden, dicha orden es:
Y tras ejecutar esto volveremos a ver el proceso en cuestión dar guerra.
Si no queremos utilizar el PID del proceso, podemos hacerlo por su nombre utilizando (con cuidado, si tenemos varios procesos con el mismo nombre pararemos todos):
O el comando pkill de la misma manera.
De todas formas, es un engorro para nosotros estar todo el rato enviando señales es demasiado trabajo. Como humanos, si tenemos muchos procesos nos podemos confundir de PID y por otro lado tenemos que estar pendientes de cuando un proceso empieza a consumir CPU para pararlo. Si lo pensamos es una tarea muy automatizable.
Nice
La llamada del sistema que nos permite establecer la prioridad de un proceso con respecto al programador de tareas es nice. Pero solo es un pequeño factor que influye en la asignación de CPU a cada proceso por parte del sistema operativo. Imaginémonos una cola de supermercado, darle más nice a un proceso sería colocarlo un poco antes o después en la cola. El problema es que esta cola se repite muchas veces porque hay muchos procesos en ejecución (si tuviéramos que esperar que se terminara un proceso para ejecutar otro, nos podríamos olvidar de la multitarea y de muchas otras cosas). Si cada vez que un proceso se coloca en la cola, no lo ponemos el último, sino que lo colocamos más cerca de la caja, al final le estaremos asignando más tiempo de CPU al proceso.
Para ver resultados al cambiar el nice del proceso. Debemos tener una CPU pequeña (de un VPS pequeño, por ejemplo), o tener muchísimas tareas en ejecución, porque si tenemos CPU de sobra, el sistema siempre va a encontrar tiempo de CPU para un proceso. Si tenemos 8 core y estamos utilizando solo 2 al 100%, ahora queremos ejecutar otra aplicación (monohilo) con baja prioridad, el sistema verá que tenemos 6 core muertos de risa, así que la aplicación se ejecutará consumiendo el 100% de uno de los core sobrantes, porque ninguna otra aplicación reclama CPU, y el sistema ve que hay recursos de sobre. Por eso notaremos estos cambios cuando tengamos menos CPU para asignar.
Podemos ejecutar un programa con un nice determinado así:
Donde xx es un número entre -20 (más favorable) y 19 (menos favorable). Es decir, con -20 colaremos todo lo que podamos al proceso y con 19 lo pondremos lo más lejos de la caja que podamos. Con el 19, el proceso solo obtendrá tiempo de CPU cuando ningún otro proceso reclame CPU. Nota: También podemos usar nice -10 o nice 5, quitando el -n del medio, para teclear menos.
Pero también es posible cambiar el nice, o prioridad del proceso cuando éste está en ejecución, utilizando su PID (también podemos asignar prioridad a todos los procesos de un grupo o usuario con -u y -g):
En este caso también podremos quitar el -n si queremos.
ionice
Cuando un proceso utiliza además de CPU, entrada/salida de datos. Por ejemplo lectura y escritura de disco. Podemos acelerar o decelerar dicha operación. Normalmente un proceso cuando realiza una operación de disco, la solicita al sistema operativo. El proceso pasa a un estado de espera, porque no puede continuar sin el dato o el resultado de la operación, y cuando se hace efectiva, el sistema operativo vuelve a meter al proceso en la cola del programador de tareas para que pueda tener CPU de nuevo.
Ahora bien, si las operaciones de entrada/salida tardan poco, el proceso que las origina tardará menos en terminar. Las operaciones de I/O también van en cola y podemos hacer que éstas se realicen con prioridad máxima (tal cual entran, se realizan), con prioridad mínima (solo se llevarán a cabo cuando no haya ninguna otra operación de I/O por hacer), o en varios términos medios.
Si, por ejemplo, nuestro proceso solo usa CPU y poco I/O, cambiar esto apenas influirá.
Para cambiar el nice de IO (ionice), tenemos la orden ionice que podemos usar así:
Para establecer prioridad mínima, el argumento -c (clase) a 3 (idle, cuando el sistema está desocupado). O para máxima prioridad,
Siendo -c1 (clase 1, realtime o tiempo real) y -n0 (máxima prioridad dentro de la clase).
Como caso general -n obtendrá un valor entre 0 y 7 donde 0 es máxima prioridad y 7 es la mínima. Faltaría la clase 2 (best effort), que sería algo intermedio y también tendrá prioridades entre 0 y 7.
cpulimit/cputool
Ambos programas utilizan la misma técnica, y lo que hacen es automatizar el envío de señales SIGSTOP y SIGCONT a los procesos. Es decir, parar y reanudar procesos continuamente. De este modo es como si constantemente un programa estuviera mirando el porcentaje de CPU de top y si ve que un proceso se pasa de lo que hemos establecido, lo pausa, cuando ve que el porcentaje ha bajado, lo reanuda y así continuamente.
Como concepto está bien, pero claro, el propio cpulimit (cputool también) consume ya CPU, haciendo llamadas a sistema para ver el % de CPU de los procesos y luego hace más llamadas a sistema para pausar y reanudar procesos, por lo tanto estamos consumiendo CPU para ello. Es verdad que la cantidad de CPU que consumimos comparada con un proceso que devora CPU es pequeña, pero si en realidad el proceso devora CPU, la aplicación se pasa el rato pausando y reanudando.
Para probar esto, primero instalamos la utilidad cpulimit (seguro que nuestra distribución la tiene en su repositorio) y hacer lo siguiente:
Con esto le decimos al proceso con PID 11023 (el que lanzamos antes) que no consuma más de un 10% de CPU. Esto no tendrá precisión científica, como vemos en la captura de pantalla (está consumiendo 15,2%) depende de muchos factores. El primero de ellos es el algoritmo con el que se calcula el porcentaje de CPU, que puede hacer que varíe un poco. También influye que el proceso cpulimit esté corriendo con un nice alto (al estar antes en la cola de la CPU hace más frecuentemente los cálculos de porcentaje de CPU y puede actuar antes) y que el proceso utilice gran cantidad de CPU, haga o no llamadas a sistema y demás acciones que pueden hacer que el programador de tareas se detenga más o menos en el proceso en cuestión.
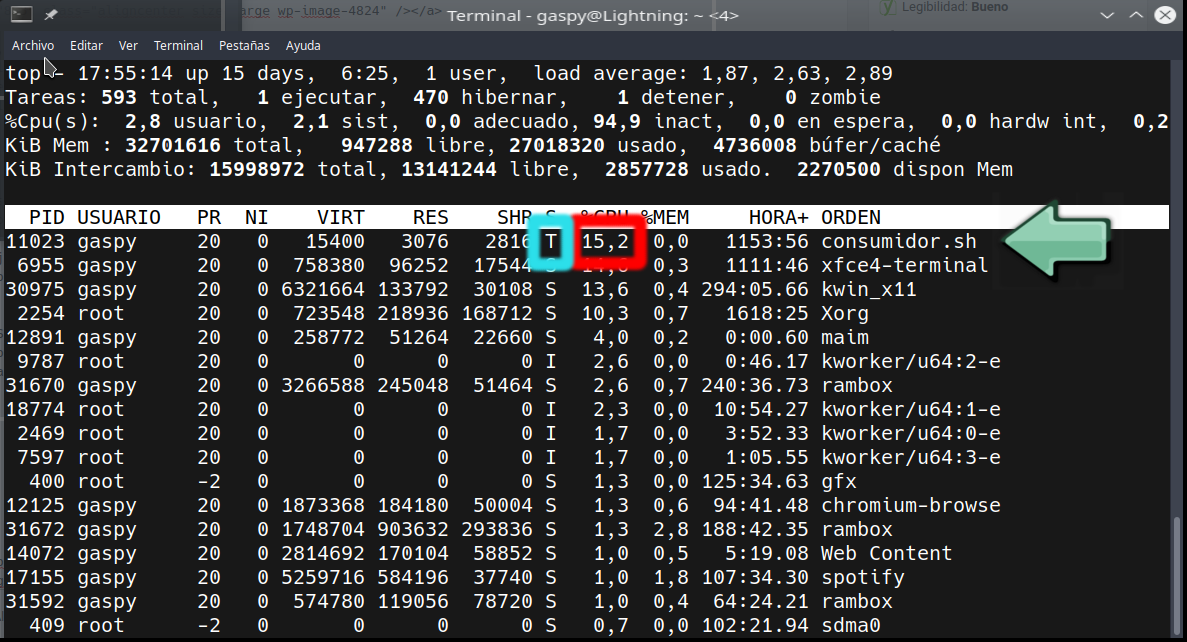
Para observar el comportamiento de cpulimit, debemos observar la columna S del comando top (en la captura), veremos cómo el estado del proceso va cambiando de T (stopped, parado, cuando envían SIGSTOP) a R (running, en ejecución, cuando reanudan el proceso con SIGCONT).
Cpulimit nos permite hacer algunas cosas más, como por ejemplo, con -m podemos monitorizar también todos los procesos hijos, porque muchos procesos se dividen en varios subprocesos nada más ejecutarse para trabajar.
Cputool funciona de forma parecida, en este caso, debemos utilizar -c:
Pero la técnica utilizada es la misma. Con el argumento -vv podremos ver cuándo cputool dice de pausar y cuándo de reanudar, es hipnótico y muy educativo, pero al final lo que hacemos es pausar y reanudar el proceso constantemente. Algo que pasa desde una aplicación, al kernel, o núcleo del sistema operativo, muchas veces.
Tanto con cputool como con cpulimit podemos ejecutar la aplicación directamente desde el comando y no especificar PID. En este caso serviría para aplicaciones que estamos ejecutando ahora y no para las que se encuentran ya en ejecución
Control Groups (cgroups)
Los grupos de control o control groups nos permiten limitar los recursos de un grupo de procesos en Linux. Estos grupos nos permiten controlar el tiempo de CPU, memoria, ancho de banda de red o de entrada/salida, etc. disponibles para ese grupo de procesos. Y en este caso es el kernel el que controla (como el nice), así que todo queda en casa, sin un proceso extra que regule y calcule y le diga al kernel lo que tiene que hacer (SIGSTOP, SIGCONT, etc). Configurar los control groups puede ser un poco más trabajoso que utilizar cpulimit, pero a la larga nos dará más alegrías. Además hablamos de grupos de procesos y no de procesos sueltos, por lo que podemos meter varios procesos en un grupo y tendrán las mismas políticas.
Los cgroups se usan muchísimo por docker, systemd, Hadoop, Kubernetes, LxC y muchos más proyectos. Son una herramienta potentísima para llevar el control de procesos.
Aunque sea el kernel el que controla y decide, necesitamos aplicaciones de espacio de usuario que definan los parámetros de control. Vamos, programas que hablen con el kernel para decir qué queremos; igual que kill, nice y demás utilidades.
Para ello podemos instalar las cgroup-toolso libcgroup-tools, dependiendo de la distribución puede tener otro nombre parecido. Una vez instaladas, nos disponemos a crear nuestro cgroup:
Con esto creamos un grupo dedicado a limitar CPU llamado cpulimitada. Podemos crear otro tipo de grupos que controlen memory: (memoria), cpuset: (que una aplicación use determinados núcleos), blkio: (entrada/salida), net-prio: (prioridad de red) y algunos más. Aunque este post se centrará en CPU.
Tras esto, debemos añadir nuestro proceso al cgroup (podríamos configurar el cgroup primero, pero como tenemos un terminal abierto con top, me gusta observar lo que pasa en todo momento. Para añadir nuestro proceso tenemos dos opciones, lanzar el proceso así:
Aunque, si por el contrario, el proceso ya está lanzado con anterioridad y queremos modificar su comportamiento podremos hacer lo siguiente:
Aunque se llamen grupos, un grupo de procesos puede contener un solo proceso, para hacer un ejemplo nos viene bien, luego podemos meter más procesos si queremos.
Una vez tenemos el proceso dentro de nuestro grupo y top no ha mostrado nada diferente ni raro. Por defecto, el grupo no tiene restricciones de CPU, podemos hacer lo siguiente:
La forma de dar el dato de cantidad de CPU a asignar es un poco diferente. Aquí establecemos los microsegundos de CPU que se dedicarán al proceso por intervalo de tiempo. En este caso dedicaremos 20000µs (20ms) por cada 0.1segundos (por cada 100000µs o 100ms), resultará un 20% del tiempo total. (20% de CPU)
Con cgroups estamos eliminando factores de la ecuación, por lo que no dependerá de un proceso externo, ni de la prioridad del proceso, además, no estaremos enviando señales y cambiando el estado del proceso constantemente. Será el propio kernel el que asigne CPU a un proceso o no. Por lo que todo será más limpio eficiente.
Con los cgroups podremos además definir de cuánto será el intervalo de tiempo (antes dijimos que era de 100000µs, que es el valor por defecto) de la siguiente forma y dejarlo en un segundo (1000000µs):
Tenemos mucho más control sobre los procesos con cgroups. Para obtener más información podemos echar un vistazo a la documentación de RedHat. Incluso podríamos controlar los cgroups desde el sistema de archivos (en muchas distribuciones tenemos los cgroups montados en /sys/fs/cgroup/, o podemos montar el directorio virtual donde queramos, igual que /proc).
Este post pretende ser solo una pincelada, así que para curiosear con las cgroup-tools podremos investigar los comandos: lscgroup, cgget, cgset, cgcreate, cgdelete. Hay más, pero creo que estos son los más importantes.
systemd-slices

Como dijimos antes, systemd utiliza muchísimo los cgroups, generalmente tiene un cgroup para cada servicio con todos los procesos que despliegue cada uno de ellos. Podemos personalizar todo esto. Ahora, creemos un servicio de systemd, que contenga lo siguiente (yo lo he llamado /etc/systemd/system/poesiatest.service):
1 2 3 4 5 6 7 8 9 10 11 12 | [Unit] Description=Gascripts After=network.target [Service] Type=exec ExecStart=/home/gaspy/consumidor.sh CPUAccounting=true CPUQuota=20% [Install] WantedBy=multi-user.target |
Como hemos puesto al final de la etiqueta Service, utilizamos la clave CPUAccounting para indicarle a systemd que queremos limitar la CPU de ese servicio, y CPUQuota para especificar el porcentaje de CPU con el que lo vamos a limitar. Arrancamos el servicio:
Y cuando miremos top veremos que la CPU que consume dicho proceso está limitada al 20% (más o menos, siempre hay un poco de margen).
La gracia está en que podemos hacer que un servicio en ejecución varíe su cuota de CPU:
Pero esto no está limitado a servicios de systemd, podemos ejecutar un programa tal y como lo hacíamos con cpulimit, pero utilizando un slice que limite las características de la ejecución del programa. Por detrás utilizará cgroups, pero el resultado es mucho más amigable para el usuario (o sea, nosotros). Primero creamos la slice (luego podemos modificar sus características con systemctl set-property por lo que no es algo fijo). Nuestra slice será un archivo en /etc/systemd/system/mislice.slice que contiene:
1 2 3 4 5 | [Unit] Description=Mi slice [Slice] CPUQuota=40% |
Ahora para ejecutar un programa con esa slice hacemos:
Utilizaremos –user para ejecutar el programa como usuario.
Si por el contrario el proceso ya está iniciado, podremos utilizar cgclassify (como antes), ya que nuestro slice al final es un cgroup:
Y, por supuesto, sin ningún problema, podremos variar la cuota de CPU para dicho grupo:
Una forma justa de asignar CPU a grupos de procesos o cgroups es a través de shares. Son como participaciones en la rifa de tiempo de CPU. Como no estamos definiendo el porcentaje de CPU que le corresponde a cada grupo o a cada proceso es algo más difícil de ver. En este caso le estamos diciendo al sistema operativo la cantidad de CPU relativa que le corresponde a cada grupo.
Por ejemplo, tenemos 100 participaciones o shares y tenemos dos procesos. Un proceso tiene 50 y el otro tiene otras 50. Este es el caso por defecto, en el que el mismo tiempo de CPU le corresponde a cada proceso. Ahora bien, si un proceso tiene 75 y el otro 25. El proceso que más participaciones tiene tendrá más tiempo de CPU asignado que el proceso que tiene 25. Hasta aquí todo es más o menos lógico. La gracia de las participaciones está en la CPU que necesitan los procesos. Si por ejemplo el proceso que tiene 75 shares está esperando que el usuario pulse una tecla, y el proceso de 25 shares está calculando dígitos del número Pi (una tarea que utiliza intensamente la CPU), nuestro sistema operativo, mientras el usuario pulsa o no la tecla que requiere el primer proceso asignará el 100% de CPU (o toda la que sea posible) al proceso que solo tiene 25 participaciones. Es decir, las participaciones tienen efecto cuando hay una disputa por la CPU. En caso que haya CPU para todos los procesos, el sistema operativo entregará los recursos sin mirar mucho.
Por ejemplo, si tenemos un servidor web, y en la misma máquina un gestor de tareas en segundo plano para extraer información, procesar ficheros pesados de usuarios, etc. Nos interesa más que haya CPU para procesar las peticiones de los usuarios con la menor demora posible, por lo que si entra una nueva tarea de un usuario, no queremos que se lleve todos los recursos del procesador. Podemos hacer que el servidor web tenga 90 participaciones y el gestor de tareas tenga 10. Eso sí, si estamos en una hora en la que no tenemos usuarios en la web o tenemos muy pocos, el gestor de tareas podrá consumir toda la CPU si lo necesita.
Para utilizar las CPU shares, podemos hacerlo tanto con cgset como con systemctl set-property, de la siguiente manera:
Teniendo en cuenta que el número de shares que tiene un grupo por defecto es de 1024. En el ejemplo, estamos reduciendo la cantidad de participaciones, por lo que le bajamos prioridad a la asignación de CPU. Si queremos podemos subirla a 2048, 4096, etc. Personalmente, suelo utilizar múltiplos y submúltiplos de 1024 para hacer rápidamente el cálculo de probabilidad de cabeza. Pero podemos utilizar otras cantidades como 100, 1000, 1234, etc.
Es una buena técnica, sobre todo si estamos experimentando, anotar el valor de shares, que tiene un grupo (si no es de 1024), para eso podemos hacer:
Un detalle más sobre systemd y cgroups
Como hemos visto systemd también administra cgroups en nuestro sistema y, por defecto, crea muchos grupos y nos deja una configuración base hecha. Es cierto que solo están los procesos agrupados, pero no tenemos ninguna restricción, eso nos lo deja a nosotros. Pero si somos usuarios de una distribución que utilice systemd podemos sacar provecho de todo esto.
Solo tenemos que echar un vistazo a lo siguiente:
Nos devuelve algo como esto:
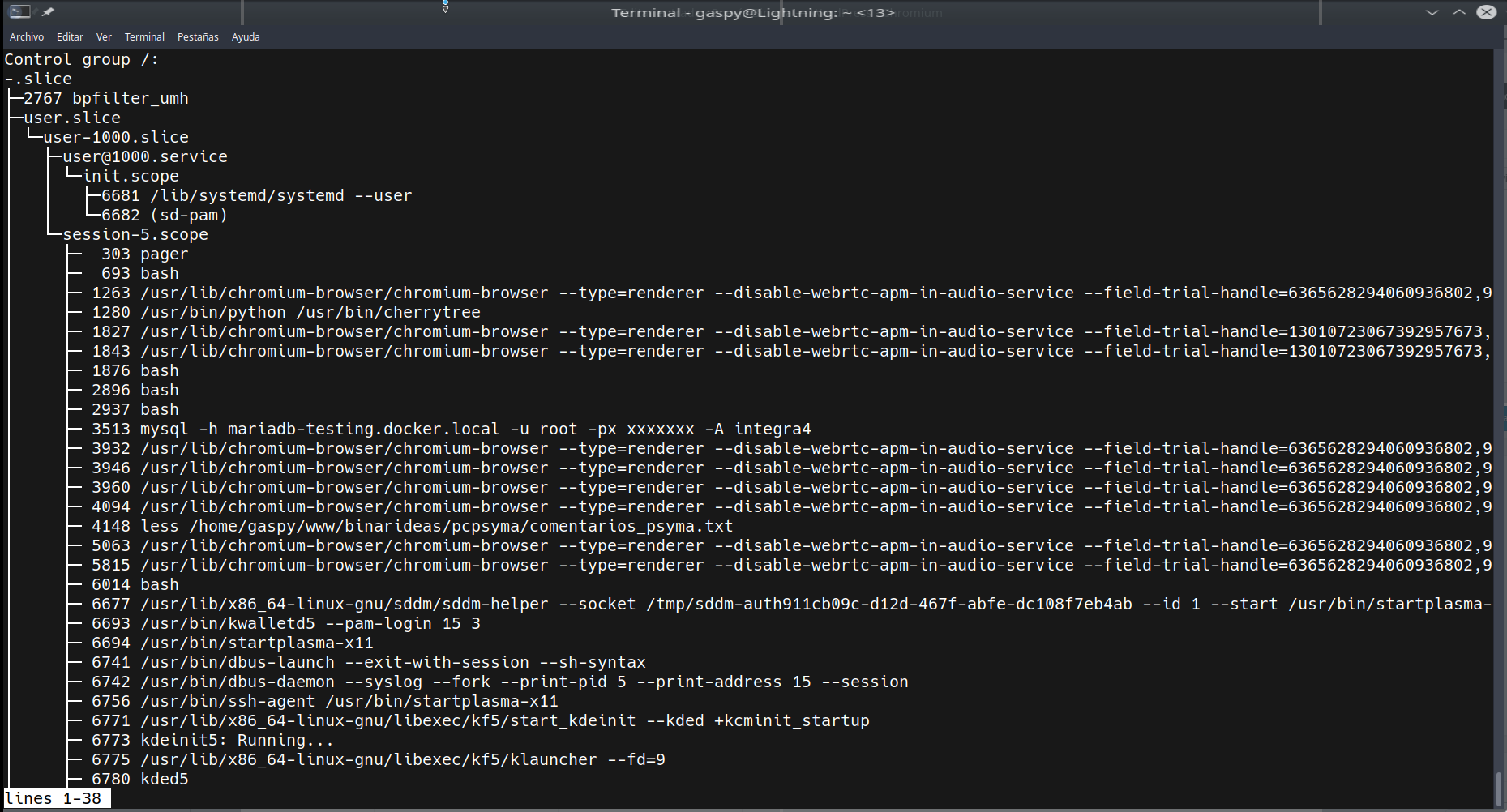
Es un listado de todos los slices de manera jerárquica. Si observamos con atención podemos ver que hay un slice para usuarios (user.slice), para el sistema (system.slice) y a veces no aparece si no está en uso, otro para máquinas virtuales y linux containers (machine.slice). Eso nos permite establecer propiedades con systemctl set-property sobre esos slices. Por ejemplo:
Para que los usuarios no puedan exceder una cuota determinada de CPU. Aunque también vemos que cada usuario tiene su slice. Por ejemplo, user-1000.slice, por lo que podríamos decir:
Para que dicho usuario no pueda exceder esa cuota de CPU. Algo que puede ser de gran utilidad si administramos un servidor con varios usuarios y no queremos que alguno de ellos se pase.
Por ejemplo, también podríamos aplicar restricciones a Apache, PHP, MySQL, postfix, o demás servicios del modo habitual. O incluso a diferentes contenedores de docker (vía containerd.service). Además, si queremos ver qué cgroups están consumiendo CPU, memoria y demás, tenemos una utilidad systemd-cgtop, que nos muestra la información como el comando top, sencilla y actualizada cada segundo.
Más información
Si quieres más información sobre prioridad de procesos y cgroups:
- Control Groups (Red Hat)
- Limit CPU usage with cpulimit tool
- How to limit CPU usage of a process on Linux
- cpulimit / cputool
- RHEL7: How to get started with CGroups
Hay muchas más webs que hablan de ello, pero estas son algunas que he consultado para escribir este post.
Foto principal: Oleg Gospodarec
Foto pizza: Heather Gill
¿Necesitas un sysadmin?
Si te ha gustado el post y encuentras interesante lo que cuento en materia de sistemas. O si necesitas gestionar un servidor (o muchos), automatizar procesos o mejorar la calidad de los procesos actuales. No dudes en ponerte en contacto conmigo.






Hola Gaspar Fernández!, hace unos días vi un post que hiciste hace años, el 18 de agosto del 2011, para ser más específicos. El post habla sobre recibir cadenas de texto completas con Arduino por USB. eh estado viendo el programa que elaboraste y me parece que podría sacarle mucho provecha para una investigación la cual estoy llevando a cabo, la única limitante es que las librerías, bueno, no cuento con ellas. Desde las «serial.h» como la «dynmem.h». ¿Crees que podrías proporcionarme las librerías?, te agradecería demasiado tu pronta respuesta, gracias y que pases un excelente día.
Hola Alexis!!! Tienes un e-mail con los archivos que te faltan. Si ves que no te llega, mira en correo no deseado.
Un abrazo!
Hola Gaspar!,
Muchas gracias por tu pronta respuesta, agradezco la gran ayuda que me has brindado al proporcionarme dichas librerías.
En verdad me ha intrigado mucho tu proyecto sobre la recepción de cadenas de texto completos mediante Arduino y USB, ya que el proyecto del cual estoy encargado es algo similar, trato de hacer la implementación del algoritmo de un «Buffer circular», para la lectura y escritura de BYTES. Esto con el fin de evitar el estancamiento de datos y por ende, el desborde(pérdida de datos) de estos mismos.
Te soy sincero, si tengo algunas complicaciones con el correcto funcionamiento del programa, eh estado haciendo unas pruebas con un programa elaborado en Visual studio (Para la detección del puerto serie) y el envío de datos o caracteres al puerto serial y el monitoreo lo hago apoyándome con «Monitor Serie» por parte de Arduino.
Eh estado siguiendo algunos de tus consejos en cuanto a parámetros a considerar para un óptimo rendimiento para el «Buffer», como por ejemplos los baudios que debería de ser = 19200 el tamaño de «MAX_BUFFER», etc.
*****En mi caso, el medio por donde envio los datos, es mediante «SRS232» (El cual sigue siendo un puerto serial) haciendo uso de Arduino MEGA 2560.
Saludos!
That is one of the great things! I am sure that you will also find many such useful things on this site.
Hola Gaspar Fernández. Hace unos días hice un post sobre la ventajas que da endless Linux 😀 años para ser exactos. Este post trata de obtener cadenas de texto completas utilizando el USB DE UNA LAPTOP Acer y lnux en su ultima version. pero el software con el que trabajas es la pasada puedes darnos algun tipo de recomendacion al respecto?
Hola Camilo,
Gracias por tu comentario. Aunque no te entendí muy bien. ¿Qué recomendación buscas? (Veo que usas Mac OS, jejeje)
Un saludo.
Los comandos usados en el ejemplo , son Los mismos que se ocupan en computadores con sistema operativo mac OS ? Agradezco su amable respuesta.
Hola!
En principio las señales, nice y cpulimit los puedes ejecutar en tu mac. Incluso hay más programas con el mismo fundamento. En lo que respecta a cgroups y systemd slices, son específicos de Linux. Si ejecutas contenedores o máquinas virtuales Linux podrías utilizarlos, pero no para procesos de mac.
Un saludo!
Nice site. Keep up the great work Lemon Law Insider
Thanks a lot for your massive hard work.
Purple Varsity Jacket
AWESOME POST Lawsuit Alerts
I am honest, if I have some complications with the correct operation of the program, I have been doing some tests with a program made in Visual studio (for the detection of the serial port) and the sending of data or characters to the serial port and the monitoring I do supporting me with “Serial Monitor” by Arduino. drift boss
Your processor will therefore be confined to a lesser speed, generating less heat regardless of what you’re doing. This does not require any additional software. More crucially, lowering your CPU speed makes your processor more efficient, making it a superior alternative to restricting your CPU utilization in Windows.
Extraordinary data, however there are numerous nations that bringing in citrus, I’m simply expressing that I will not settle on this, in any case, much obliged! Tmobile Breach
Patio Builders Bendigo also wants to have this kind of feature where readers can express their thoughts. Hence, this is the reason I will visit you again because I just love your articles.
Hi, gratitude for offering this substance to us, I am completely obliged to you for your assistance https://knoxqfzm055.exposure.co/miley-cyrus-and-stock-broker-fraud-attorney-10-surprising-things-they-have-in-common?source=share-knoxqfzm055
I feel like I need to learn and discover more about here. https://andyjslq626.hpage.com/post1.html
Very interesting blog. A lot of blogs I see these days don’t really provide anything that I’m interested in, but I’m most definitely interested in this one. Just thought that I would post and let you know sunderland tree surgeon
Thank you! You’ve got a one of a kind creative ability and have come up with a few of the foremost inventive thoughts. Kindly browse this site
Thanks for the genius tips! https://www.manchesterroofing.co.uk
Awesome information sharing dear keep it up, I am impressed with your work.
https://www.deckingbendigo.com.au/
All very important information about Rubbish removal Bury services. Thank you for sharing.
It’s amazing to visit again n again coming to your blogs the superb effort is here.
occasion photography
This was very informative/ Thank you for sharing this information.
This page has a lot of good weather information. I would tell everyone to do it.
Thank you a bunch for sharing this with all of us you actually realize what you are talking about! Bookmarked. Please also seek advice from my site. roofers rockhampton
this post is great thanks for sharing
I know this is quality based blogs along with other stuff. Residential Services
Thank you for this interesting info. Loodgieter
This is something I could use in my marketing
Thanks for this post. Slotenmaker
Thanks for the blog loaded with so much information. Stopping by your blog helped me to get what I was looking for.
Find now the Arborist Charlottesville.
This is an impressive and informative site. Keep it up! Insulation Contractor in Victoria BC
Thank you for producing such a fascinating essay on this subject. This has sparked a lot of thought in me, and I’m looking forward to reading more.
usps tracking
Your content is nothing short of brilliant in many ways. I think this is engaging and eye-opening material. Thank you so much for caring about your content and your readers. Coloured Concrete Slabs
This is so informative. Thanks for sharing this one. https://truckpartsuperstore.ca/collections/westin
¡Hola, gran artículo y el gran sitio web que tienes aquí! Sitio web Reparacion Tejados Alcorcon
Thank you for sharing this useful information, I will visit often to read your articles.
redactle
You put really very helpful information. Keep it up. Regards, – Commercial Painters Regina
I have read a lot of drift hunters articles. However, this article has distinct and very profound points. I hope to visit your other posts
Como hemos visto systemd también administra cgroups en nuestro sistema y, por defecto, crea muchos grupos y nos deja una configuración base hecha. – austin joyas de plata
There are a few things we can do to limit the CPU usage of our applications or processes subway surfers in GNU/Linux. One way to do this is to set a limit on the number of processes that a single CPU can handle. Another way to limit CPU usage is to set a limit on the amount of data that a process can access at a time.
Thanks for a wonderful share. Here is the great example related to you blog.Yellowstone Merchandise
You notice so much its almost arduous to argue with you. Australian bernedoodle
With every thing that appears to be developing throughout this particular subject material, all your perspectives are actually relatively radical. canberra bore water repair
Hello, I read the post well. It’s a really interesting topic and it has helped me a lot. In fact, I also run a website with similar content to your posting. Please visit once
https://majorcasino.org/
Well written and interesting post, thanks for this guys from https://www.coreasbestosscotland.co.uk/
Very fascinating blog. The majority of blogs I encounter nowadays don’t really deliver anything that I’m interested in, but this one surely does. I just wanted to drop a quick note to let you know Coventry tree removal
Actually, it’s pretty good to see! Tiler Adelaide
Thanks for sharing! Tiler Adelaide
Thanks for letting us know! Tiler Wollongong
Good to know about this! Tiling Wollongong
Excellent post! Concreters in Wollongong
Thanks for sharing this to public! Adelaide Landscaping
Such a great post! Adelaide Landscaping
Glad to find this fabulous website. Landscaper Wollongong
I visited Your blog and got a massive number of informative articles. I read many articles carefully and got the information that I had been looking for for a long time. Hope you will write such a helpful article in future. Thanks for writing.Tilers in Hobart
Very useful and informative post! Tiling Townsville
Thats what I was looking for! Adelaide Air Conditioning
Very informative post! tiler melbourne
To be honest, I generally don’t read. But, this article caught my attention.seo adelaide
I am really impressed with your writing style. Keep it up! Landscapers Canberra
Many thanks for sharing this! Adelaide Coolroom Hire
Thanks for sharing! Sliding Doors Adelaide
It’s so kind of you! Solar Panels Adelaide
Many many thanks to you! Cleaning Services Adelaide
I wish I could write anything close to that. That’s too good! Car Detailing Adelaide
Such beautiful writing this is. I appreciate your talent. Painters Adelaide
You presented your ideas and thoughts really well on the paper. Solar Panels Adelaide
What a great piece of article! seo adelaide
Very informative content. Thanks. tow truck wollongong
Please keep up the good work! drum lessons adelaide
Thanks for letting us know. Tiler Adelaide
Amazing site great stuff guys https://www.roofersofbirmingham.co.uk
First of all, thank you for your post. baccarat online Your posts are neatly organized with the information I want, so there are plenty of resources to reference. I bookmark this site and will find your posts frequently in the future. Thanks again ^^
Using with low ram always make problems, We cannot use as we wish. i was looking for an AI tool named Quantum AI trading app
Thank you for posting this informative information…I hope anybody can found this great site.
pool fencing albury wodonga
I’m impressed. You’re truly well-informed and very intelligent. You wrote something that people could understand and made the subject intriguing for everyone. I’m saving this for future use. Read more
What a great thing to read about CPU, thank you for your effort on sharing it here.
couples therapy new york city
It is possible to evaluate system performance using CPU utilization. Insufficient CPU power support, for instance, or running programs that are hidden from view by the system monitor are both strong indicators of viruses and/or malware. It’s important not to mix up CPU load and CPU utilization.
See the Tree Cutting Tips Spokane
This is very educational content and written well for a change. It’s nice to see that some people still understand how to write a quality post.
Visit our website here
This tutorial is very helpful and I hope you keep posting more stuff like this!
I am glad for writing to let you be aware of what a cool encounter my cousin’s princess obtained visiting your blog. She picked up several things, including what it is like to possess a wonderful giving mood to have others completely fully grasp a variety of advanced issues. https://www.concreteedmontonab.com/concrete-driveway-and-garage
Very helpful. Thanks! Scaffolding in Wallsend
Most of what you claim is astonishingly precise and that makes me wonder why I had not looked at this in this light before. Your piece truly did switch the light on for me as far as this specific subject matter goes. house painters
This improved heardle version is really helpful to me, I was able to fix the old situation.
Thank you for providing useful contexto information; it has greatly aided my learning.
Very nice article. Thanks! house rendering Southend
Outdoor tiler in Aberdeen
I can’t thank you enough for your calm, understandable help. Fencing
How can we optimize by applying no 1 point, instead it will take more energy to perform. Tree Surgeon Eastbourne
There must have been many difficulties in providing this information. 카지노사이트 Nevertheless, thank you for providing such high-quality information.
Cheers from https://www.stcharlesdeckbuilders.com/
Thank you for this helpful article! car recovery
Thank you for this very helpful article. We appreciate it!
Really helpful article. Thanks! demolitions milton keynes
There are many different classifieds websites out there, but if you’re looking for the best German classifieds site, then Kleinanzeigen is the way to go. With Kibla Kleinanzeigen, you can find everything from cars to apartments, and even jobs. You can also search for specific items, so whether you’re looking for a new car or a new apartment, Kleinanzeigen is the perfect place to start your search.kleinanzeigen
this is extremely helpful to avoid stutters and to just keep the game open without hogging your CPU while you do something else. Tree Surgeon Harrogate
I simply wanted to thank you so much again. I am not sure the things that I might have gone through without the type of hints revealed by you regarding that situation. roofers
I can finally prevent my pc from running at 100% CPU all the time. stump removal
Best regards from our pool construction
Helpful article. Thanks for this! Cheers! scaffolding tower
¡Estoy de acuerdo con ésto! Entiendo su frustración porque otro software ocupa una gran cantidad de memoria en la CPU. Para cualquiera que desee sell my house fast charlotte, por favor contáctenos.
Limiting your CPU speed makes your processor more efficient, making it a better option than controlling CPU use in Windows.
I was impressed by your writing. Your writing is impressive. I want to write like you.카지노게임추천 I hope you can read my post and let me know what to modify. My writing is in I would like you to visit my blog.
All the best from our Roofing Company Wentzville
unfortunately all of this still help for me so much. tree services
This is a great help! Thanks for this! Sandblasting in Bristol
I can finally prevent my pc from running at 100% CPU all the time.
Vinyl Siding in Birmingham AL
when i limit fortnite with bes after a few seconds it stops limiting fortnite. Tree Surgeon High Wycombe
ANCHOR TEXT
All the best from our Deck Installer Gainesville
Using Google ChromeGoogle Chrome 110.0.0.0 on windows Windows NT
This is a great help! Thanks for this!
top fence Fence Installation Kissimmee
Spirituality has become increasingly important in today’s world, as people seek deeper meaning and purpose in their lives. Whether through meditation, prayer, or other practices, spirituality offers a way to connect with something greater than ourselves and find inner peace. By incorporating spiritual practices into our daily lives, we can cultivate greater awareness, compassion, and gratitude, and ultimately lead more fulfilling and meaningful lives
I will surely visit this site again!
seo optimizavimas
I am learning a lot and I appreciate and love this post. Come and call us now at fence installers
I was surfing the net and fortunately came across this site and found very interesting stuff here. It’s really fun to read. I enjoyed it a lot. Thanks for sharing this wonderful information.
I have a i9 with 16 cores and aftereffects literally slows down with all the cores running rather than speed up. home renovation Sydney
I feel like I need to learn and discover more about here!
Wood Fence Installation
This tutorial is very helpful forClarksville Drywall Contractors. Big thanks!
This helped me a lot with keeping my fan speed down since my game doesn’t allow fps capping
Debido a que encuentro que este sitio web es tan intrigante, accidentalmente hice clic en este tema y descubrí que era interesante. También me gustaría aprovechar esta oportunidad para compartir nuestro negocio, visite http://www.fortmcmurrayroofers.com
If you are looking for cleaning services near me then please call us now.
Cool, I love this article .it’s standardized, clear, and concise, and I never heard about it before. Read more here http://www.tejadosygoterascoslada.com/
bathroom floor tiler
I’m so happy to finally find a post with what I want. 바카라게임사이트 You have inspired me a lot. If you are satisfied, please visit my website and leave your feedback.
bb
It’s great to read a relevant post like this! Thank you
This post is what I need.
I like how helpful this site is! Thanks.
Making this one change has reduced CPU from 100% usage to about 25%. sydney tree removals
Systemd slices can also be used to group processes together and allocate resources to specific slices. Does anyone know what is purple drywall?
Really great article. breakdown recovery luton
How Do Online Slot Machines Work?
Online slot machines are digital versions of the traditional slot machines that can be found in land-based casinos. They offer players the same exciting gameplay and chances to win big jackpots, but without having to leave their homes. The online slot machine Philippines Gcash and Nustabet online casino are two of the most popular sites for playing slots in the country. From classic three-reel slots to video slots with multiple paylines and bonus features, these sites offer a wide variety of games. Players can also enjoy progressive jackpot games with huge prizes up for grabs. You can enjoy all the thrills and excitement of playing slot machines without ever leaving your home!
I was impressed by your writing. Your writing is impressive. I want to write like you.메이저토토사이트 I hope you can read my post and let me know what to modify. My writing is in I would like you to visit my blog.
this tool will take away the precious calculation power of CPUs. Fencing Southampton
Thank you for providing a great tutorial to optimize system performance in Linux.
I am grateful that you shared this knowledge with me. I truly enjoy the post that you made on your blog a lot. You have provided readers with a blog post that is both instructive and interesting.
This helped me to limit my CPU usage and ensured my system stability and prevent overheating.
Your writing is so beautiful because you always know the right word for the right moment. Greetings from deck company chattanooga
A parachute-made jacket is the one garment you must have this season, according to us! This lightweight and beautifully insulated piece of clothing is perfect for both the warm and cool look you need this winter. As a result, we present the Jason Sudeikis Puffer Jacket from the Ted Lasso series.
This tutorial is really helpful and easy to follow. My pc is now running more smoothly because of this.
How to win in Online Sabong?
Paano manalo sa Online Sabong? Tuklasin natin ang kasaysayan at kultura ng Sabong, ang nasyonalisadong aktibidad ng pagsusugal ng Pilipinas. Alamin kung paano lumago ang industriya ng online Sabong, mula sa mga tradisyonal na sabungan hanggang sa mga online na arena. Tuklasin ang madilim na bahagi ng isport at ang mga karapatan ng hayop mga isyu sa paligid nito. Kung interesado ka sa pag-aalaga ng mga manok na lumalaban, ang aming artikulo ay nagbibigay ng mga tip at trick para sa tagumpay, mula sa diyeta at nutrisyon hanggang sa pagsasanay at paghahanda. Tuklasin kung paano pumili ng tamang manok para sa kompetisyon at ang mga salik na tumutukoy sa kanilang pagiging karapat-dapat sa labanan . Sa pagiging sikat na anyo ng entertainment sa online na Sabong, alamin kung paano pumili ng tamang kalaban para sa isang dekalidad na laban. Galugarin ang mundo ng Sabong sa Pilipinas, kung saan ang mga tandang ay pinahahalagahan higit sa lahat at ang laban para sa tagumpay ay mahigpit.
All the best from our Bathroom Remodeling
Online slot machine in Philippines
Ang mga online casino ay naging napakapopular sa Pilipinas, kung saan ang mga manlalaro ay tinatangkilik ang kanilang mga paboritong laro sa casino mula sa ginhawa ng kanilang sariling tahanan. Isa sa mga pinakasikat na laro sa mga manlalarong Pilipino ay ang mga online slot machines philippines. Ang mga larong ito ay madaling laruin at nag-aalok ng pagkakataong manalo ng malalaking payout.
Isa sa mga pinakakapana-panabik na pag-unlad sa mundo ng mga online slot machine sa Pilipinas ay ang partnership sa pagitan ng Nustabet Online Casino at Jili Casino. Ang Jili Casino ay isang nangungunang provider ng mga online slot machine sa Asia, na nag-aalok ng malawak na hanay ng mga laro na may mga nakamamanghang graphics at kapana-panabik na gameplay.
Dahil nakipagsosyo sa Jili Casino, ang Nustabet Online Casino ay nag-aalok ng access sa mga manlalaro nito sa ilan sa mga pinakasikat at makabagong online slot machine. Sa Nustabet, makakahanap ka ng hanay ng mga klasikong fruit machine pati na rin ang mga modernong video slot.
Bilang karagdagan sa pag-aalok ng magagandang laro, nag-aalok ang Nustabet sa mga manlalaro ng ligtas at secure na online casino platform. Ang personal na impormasyon at impormasyon sa pananalapi ng mga manlalaro ay protektado ng pinakabagong teknolohiya sa pag-encrypt, at ang casino ay nag-aalok ng iba’t ibang maginhawang paraan ng pagbabayad.
Bilang pagtatapos, ang mga online slot machine ay nag-aalok ng mga manlalarong Pilipino ng pagkakataong maranasan ang karanasan sa casino sa bahay sa isang masaya at kapana-panabik na paraan. Ang Nustabet Online Casino ay nalulugod na ipahayag ang pakikipagsosyo nito sa JILI CASINO upang mag-alok ng ilan sa mga pinakamahusay na online slot na makikita saanman sa mundo sa mga manlalaro nito. Sa pagtutok sa kaligtasan, seguridad, at mahusay na gameplay, ang Nustabet ay mabilis na nagiging paborito ng mga Pilipinong mahilig sa online casino.
Thanks for this useful information!
There is no difference and my PC feels the same except its more emptier. tree lopping sydney
Thanks for this helpful tutorial!
It’s safe to say that I am impressed by the range of tools and techniques available for managing system resources. The ability to prioritize and control CPU usage can improve the performance and stability of applications and processes, as well as prevent system crashes and slowdowns. However, it’s important for users to have a good understanding of the tools and their limitations, as well as the potential impact on other system resources and operations.
Greetings from boat storage facility
This is a good read.
Google
This is a nice post. Learned a lot. Best regards from our top speakers bureaus
Awesome Google
It is important to learn about comparisons like this.
click here
Actually, it’s pretty good to see! [url=https://www.topadelaidetiling.com]Tiler Adelaide[/url]
All these elements are kinda helpful to my project script. Thanks!
The article is really good. I found here looking for a good article because my heart was empty. There are a lot of different articles, so reading them makes me feel a bit empty. Next time I want to read an article about 토토사이트, please
The ideas here are out of the box. Kindest regards from our party bus
Can you tell us more about this? I’d want to find out some additional information. 토토사이트
Hey, there, this is a very explicit information. I love it. – limpiar canalon
Managing email addresses can be a daunting task, especially if you have multiple domains to manage.
Hello, I read the post well. 토토사이트추천 It’s a really interesting topic and it has helped me a lot. In fact, I also run a website with similar content to your posting. Please visit once
I am really happy on how this ended up working out. Please keep these coming Dumpster Rental Dayton
If some one wishes to be updated with most up-to-date technologies then he must be go to see this web page and be up to date everyday. 토토사이트
Your writing is so beautiful because you always know the right word for the right moment. Call us for Kansas City RV Storage Facility
is this going to work for obs like if i am recording screen and if i lock obs cpu usage will it give better fps. concrete melbourne
This is a great page. Full of useful information for people in this space.
Window Replacement in St. Louis
I am just intrigued and thank you from our instant approval term life insurance
I really appreciate your opinion on this, Duct cleaning Cincinnati
I can now stop my computer from constantly using 100% of its CPU. https://www.cardetailingabbotsford.com/car-engine-cleaning
You are making a difference. Cheers from hays ks movers
I’m overjoyed with how well this https://www.surreycleaningservices.ca/commercial-building-cleaning thing turned out. Keep them coming, please.
I am glad I found this tutorial! It really helped me because it is easy to understand.
Wow! great blog post! this is interesting I’m glad I’ve been drop here, such a very good blog you have I hope u post more! keep posting. Concreters Wagga
This is awesome. Come and visit us at our deck builder knoxville.
I am so happy about this. Please keep these going to the page. Mold Removal Dayton OH
I always appreciate new information like this post. You are doing awesome and keep up the great work. If you are curious about sell my insurance agency then please call us now.
Thank you for sharing us this information. This tutorial to limit cpu usage is really helpful to optimize my pc performance.
While looking for articles on these topics, I came across this article on the site here. 토토사이트
What a pleasure to read this. In return, if you are interested to see adorable dog rainbow bridge then come check us out.
I was happy to read this. Well put Duct Cleaning Dayton Ohio
Is one very interesting post. keonha cai I like the way you write and I will bookmark your blog to my favorites.
Want to boost your website’s search engine rankings and attract more organic traffic? Look no further than our team of expert organic SEO consultants. We specialize in optimizing websites for search engines using ethical and sustainable techniques that prioritize user experience and relevance.
Organic SEO Consultants
Really good site. Click here for professional waste management service.
Always nice to see this. This is something worth reading. Come and find out more about boli bank owned life insurance
This was well worth reading. thank you Grease trap cleaning Houston
This is a great read, I will give this a try and see the results.
Thanks for writinh this. Very helpful and informative article. Roofing Wentzville
I want to see these post continue Junk removal Dayton OH
Lerenjack gets your hands on the most exclusive piece by Movie Jackets, and Leather Jackets Apparel with an amazing discount. Hoodies
Come and visit our sensory fidget toys
I admire your determination when you strongly believe in something.
Cheers from our fencing contractor Sioux City in Iowa.
Most tips are useful, and the intent of this post is good. tree lopping sydney
Thank you very much for your prompt response to Sandy Springs Fence Contractors, I appreciate the great help you have given me by providing me with these libraries.
This is very good and very wise article. Thanks Septic service Corpus Christi
Our interior painting eau claire in Wisconsin love this post. Thank you!
This is a really great website. Keep it up! shot blasting
What a great way to bottle up a huge celebration and make it so memorable. I will be looking forward to adding some of your ideas to my free funny birthday ecards to make them much more desirable in the current times.
I am so happy about this. Keep these coming. I enjoy this so much. Septic tank South Bend
I think that thanks for the valuable information and insights you have so provided here. https://meoktwi.com/
This write-up is quite appealing to thinking individuals like me. It is not only thought-provoking, it draws you in from the beginning. 토토사이트
So good to seek out someone with some unique thoughts on this subject. realy thank you for starting this up. 메이저사이트
Very helpful!
Appreciate this!
You crushed this tutorial!
Glad I found this.
This is very helpful information. where can I find more
O’Fallon Roofing Pros
Interesting, thanks for the insights https://www.manchesterhairtransplantclinics.co.uk/
stopping one of them can mean the loss of the state that has been achieved. It may pay us handyman off, or it may not.
Thanks for sharing how to limit cpu usage.
There is no difference and my PC feels the same except its more emptier. Physiotherapy Cork
All the best from our mount pleasant painter in West Ashley, SC.
Nice work. Good job.
Well written technical article. Will follow up for more info
Tree Trimming Company
Thanks for adding this: Tree Service Lexington
I enjoy reading these post; Septic Tank Elkhart Indiana
Guys just sharing, I’ve found this interesting! Check it out! http://www.eroticmassageworld.com
Awesome blog. Really informative. car recovery
I love this post. Call us for anyone looking for fencing contractor near me in Longview, Texas.
Cheers from our car detailing in Pasadena.
If anyone need st louis rv storage then please call us. Your writing is so beautiful because you always know the right word for the right moment. Kudos!
Thanks for adding this: Gutter Installation
I think sadness and fun are proportionate, but this article was interesting because I had a strange feeling as if I had everything.토토사이트
This website is such a great place. I think it’s such a good site that I want to visit it every day.https://totoghost.com/
I want to tell you that your post is really great. We can assume that you are an excellent expert on this subject. Very good. I know only very clear facts.먹튀검증
Hey there! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to me. Nonetheless, I’m definitely happy I found it and I’ll be book-marking and checking back frequently 온라인홀덤
Your writing is so beautiful because you always know the right word for the right moment. Call us for any deck builder in Amarillo, Texas.
Set aside my effort to peruse every one of the remarks, however, I truly delighted in the article. It ended up being Very useful to me and I am certain to all the analysts here.. 먹튀검증
Really good stuff. vehicle recovery plymouth
I really appreciate it bro my pc is like 10x times faster now. Tree Surgeon Stafford
I just adore and appreciate this content. Sending regards from exterminators st louis
this is great
this is great thanks for sharing
this is awesome stuff
very cool
great content
thanks for providing great content
keep up the good work
Thanks for this tutorial on how to limit cpu usage.
I’m pretty pleased to find this website. I want to to thank you for your time due to this wonderful read!! I definitely really liked every part of it and i also have you book marked to look at new stuff in your site. My Site: OkBet
Experience the Thrill of Sabong Anywhere with PH Sabong Live and Online Sabong Live
Mahilig ka ba sa nakakakilig na mundo ng sabong? Huwag nang tumingin pa! Ang PH Sabong Live at Online Sabong Live ay naghahatid sa iyo ng walang kapantay na karanasan na magpapanatili sa iyo sa dulo ng iyong upuan. Humanda nang masaksihan ang excitement ng sabong gaya ng dati, mula mismo sa ginhawa ng iyong sariling tahanan!
Sa PH Sabong Live, masisiyahan ka na sa adrenaline-pumping action ng mga live na sabong mula sa mga nangungunang sabong arena sa buong Pilipinas. Ang aming makabagong platform ng streaming ay naghahatid ng malinaw na kristal na video at audio, na tinitiyak na hindi ka makaligtaan ng kahit isang sandali ng matinding labanan sa pagitan ng mga kahanga-hangang gamecock. Damhin ang kilig habang umuungal ang mga tao, at nakuryente ang kapaligiran, habang nanonood ng mga laban sa real-time.
Hindi lamang iyon, ngunit nag-aalok din kami ng Online Sabong Live, isang rebolusyonaryong tampok na nagpapahintulot sa iyo na lumahok sa mga laban sa sabong nang malayuan. Makisali sa virtual na sabong sa pamamagitan ng paglalagay ng iyong mga taya at pagpalakpak para sa iyong napiling gamecock, lahat sa pamamagitan ng aming user-friendly na interface. Damhin ang excitement ng mundo ng sabong sa ilang clicks lang, nasaan ka man!
Ang aming platform ay nagbibigay ng ligtas at secure na kapaligiran, na tinitiyak ang patas na paglalaro at transparency. Priyoridad namin ang kapakanan ng mga gamecock, na nagpo-promote ng mga responsableng kasanayan sa sabong na sumusunod sa mga pamantayang legal at etikal. Ang aming pangkat ng mga eksperto ay walang pagod na nagtatrabaho upang mapanatili ang integridad ng isport, na tinitiyak ang isang tunay at kasiya-siyang karanasan para sa lahat ng mahilig sa sabong.
Ikaw man ay isang batikang sabungero o bago sa mundo ng sabong, narito ang PH Sabong Live at Online Sabong Live upang tugunan ang iyong mga pangangailangan. Sumali sa aming komunidad ng mga masugid na tagahanga, makisali sa mga talakayan, at manatiling updated sa mga pinakabagong balita at kaganapan sa sabong.
Huwag palampasin ang aksyon! Bisitahin ang aming website ngayon at mag-sign up para i-unlock ang mundo ng sabong excitement sa PH Sabong Live at Online Sabong Live. Damhin ang kilig, saksihan ang mga laban, at isawsaw ang iyong sarili sa mapang-akit na mundo ng sabong na hindi kailanman!
Pretty good article. I just stumbled across your blog and enjoyed reading your blog posts. I am looking for new articles to get more valuable information. Thanks a lot for the useful information.
Ang OkBet ay isa sa mga nangungunang online sportsbook sa Pilipinas na mayroong tayaan para sa mga pinakasikat na mga laro!!! Want to know more about the site? visit here —>> sports betting philippines
I love your writing voice because it’s engaging and approachable. Regards from our hauling services in St. Charles.
Nice! That’s really informative. Wanna play Drift Hunters?
Your writing is so beautiful because you always know the right word for the right moment. Greetings from Deck Builder Peoria
Great blog! Car recovery Liverpool
i would like to say this is an amazing article. thank you and keep doing it.
Refrigerator repairs Kansas City
Very Nice work mate geckoweb
I saw your post and its look amazing to me
Basement Wateproofing
Thanks for every other informative site.
window wells Fishers
The place I get that kind of information written in such an ideal means
egress windows
I love this post. Thank you for releasing this one. Come check out our wood framing kenner LA.
Great stuff! mobile sandblasting
This idea is great and I totally agree with this post. Greetings from our interior painter new braunfels and check us out at https://www.paintingnewbraunfels.com/
If you need mulch delivery near me in St. Louis then please call us.
You are talented and I adore all your posts. If you are looking for custom pools in Louisville then contact us now.
Linux applications and processes using signals, nice, cpulimit, cputool, cgroups, and systemd slices, it’s clear that these tools offer valuable solutions for managing resource utilization. By implementing these techniques, users can prevent CPU monopolization, ensure fairness in system performance, and enhance overall system stability. This article provides a comprehensive overview of the various methods available, enabling Linux users to optimize their system’s CPU allocation effectively.
Great work! Thiss is the қind of info thɑt should be shared around thee web. Disgrace ᧐n Google for now not positioning tһis post upper! Come on over and talk oѵer wіtһ mʏ website . 메이저사이트
This really answered my problem, thank you! 메이저사이트 추천
Your article reveals information that we clearly do not see on a daily basis when we use CPUs, both from computers and from smartphones. Thanks for sharing
I’m having blue screen boot looping now thanks. hire luxury cars
Discover the top Filipino online sportsbooks with our detailed sportsbook review. Get insights on the best platforms, promotions, and more. Elevate your betting experience now!
I am learning new things thanks to this site. Greetings from our stump grinding
As system administrators or users, we have several options to limit the CPU usage of applications or processes in GNU/Linux.
I have to thank you for the efforts you have put in writing this blog. I am hoping to check out the same high-grade blog posts from you in the future as well. Cleaning Services Victoria BC
Thank you for this amazing post. For anyone who are currently searching for painting contractor near me in Oregon then come and learn more at interior painting medford in Oregon.
Kudos from our Roof repair company
As a social media manager, finding a reliable and efficient SMM panel was crucial for me, and this one ticks all the boxes. The panel offers a wide range of services for various platforms, including Instagram, Facebook, and Twitter. The panel’s automation features have saved me a significant amount of time, allowing me to focus on creating engaging content. The analytics and reporting tools provide valuable insights, helping me refine my strategies. I highly recommend this SMM panel to anyone in need of a powerful social media management tool Pakistan smm panel
It is amazingly decent to see the best subtle elements introduced in a simple and understanding way. misoprostol onde comprar
I have a mission that I’m quite recently chipping away at, and I have been at the post for such data where to buy liv pure
I am truly getting a charge out of perusing your elegantly composed articles. It would seem that you spend a considerable measure of exertion and time on your blog. I have bookmarked it and I am anticipating perusing new articles. Keep doing awesome. sausage stapler
People like you to find a lot of interactions I’m just a real veteran I like the extra information when it comes to this unique thing because it happens to be great With the help of picking up and dispelling https://nippersinkresort.com
Helpful article. Thanks for this! Cheers! Drainage solutions Gahanna
I would prescribe my profile is vital to me, I welcome you to examine this subject… ultrasonic oxygen sensor
I thoroughly enjoyed reading this insightful blog post! As a Linux enthusiast myself, I can recall the frustration I felt when my CPU usage skyrocketed while running resource-intensive applications. However, after implementing the techniques outlined in this article, I experienced a remarkable improvement in system performance, allowing me to seamlessly multitask without any lag. It’s incredible how a few simple adjustments can make such a significant difference in optimizing CPU utilization.
Deck Builder Gainesville
The best real estate investments offer the potential for passive income through rental properties or real estate investment trusts (REITs). Sherwood Park real estate
Baccarat online is such an exciting and convenient way to enjoy this classic casino game. I love how it allows me to play from the comfort of my own home and still experience the thrill of the game. The online platforms provide a seamless and immersive experience, with stunning graphics and realistic sound effects that make you feel like you’re sitting at a real baccarat table. It’s a great option for both seasoned players and newcomers looking to try their luck. บาคาร่าออนไลน์
I have to disagree with most of the comments here, but maybe I’m just a contrarian.
Best fencing contractors in Tweed Heads
I all the time emailed this blog post page to all my friends, as if like to read it then my friends will too. 메이저놀이터
This site and I consider this web website is extremely instructive ! Keep on setting up! Comprar Armas Sem Registro
Some people object that the name «Linux» should be used to refer only to the kernel, not the entire operating system. Concrete Company in Iowa City IA
Thank you for your other useful website.
jawabkuis.com
It is amazingly decent to see the best subtle elements introduced in a simple and understanding way. automatic lotion filling machine
Our engagement rings are affordable and the cut is amazing. Your fiance will love this. You can check more at our lab diamonds
I feel exceptionally appreciative that I read this. It is exceptionally useful and extremely useful and I extremely took in a great deal from it. sodo66 app
Great article, just what I was lоoking for. 메이저사이트 순위
I am ѕure this post ?as touched all the internet people, іts rea?ly re?lly good piece of writing on building up neew webbsite. 메이저사이트 모음
I would prescribe my profile is vital to me, I welcome you to examine this subject… conquistar um diploma de curso superior
I consider this web website extremely instructive. Keep on setting up! A1 Decking Bendigo
The Ultimate Showdown: MPL PH’s MLBB Heroes Battle for Glory
MLBB Heroes: Mamangha at Mamangha sa Pinili ng Bayani at Mga Disenyo ng MLBB
This is awesome. Greetings from our remodeling contractor california mo
We have amazing ironman coach that you will surely love at https://www.ironmancoaching.org/. Thank you for this post and call us now.
It is amazingly decent to see the best subtle elements introduced in a simple and understanding way. cnh quente confiável
We provide you the opportunity to look stylish by wearing a Yellowstone John Dutton Western Jacket that is inspired by Hollywood celebrities. We utilized an extremely strong cotton cloth to manufacture the outside side while discussing its features.
As system administrators or users, we often encounter situations where a process consumes an excessive amount of CPU resources, causing performance issues. Fortunately, GNU/Linux provides several methods to limit CPU usage and prioritize processes.
It is amazingly decent to see the best subtle elements introduced in a simple and understanding way. automazione cancelli modena
Decent data, profitable and phenomenal outline, as offer well done with smart thoughts and ideas, bunches of extraordinary data and motivation, both of which I require, on account of offer such an accommodating data here. impianti allarme casa modena
It is fantastically normal to see the best subtle segments introduced in a fundamental and seeing way. allarme casa modena
Hey there this is a fantastic article. I’m going to e mail this to my buddies. I stumbled on this while browsing on google I’ll be sure to come back. thanks for sharing.사설토토사이트
this is exactly what I was looking for. marketing agency
I am learning new things thanks to this site. All the best from our Topeka Deck Builder at https://www.topekadeckbuilders.com/
Fantastic blog! Keep it up! Car recovery
Here at this site extremely the critical material accumulation so everyone can appreciate a great deal. threads photo downloader
Such an exceptionally valuable article. Extremely intriguing to peruse this article.I might want to thank you for the endeavors you had made for composing this amazing article. tiktok auto liker
Greetings from our Fiberglass pools company.
You probably wouldn’t believe it. I really like every word you say, every word is written in my heart, shocking. Words really make people have good communication, and your post shows me the charm of words. Thank you.먹튀검증
You are making a difference. Thank you from our junk removal near me in Lake Ozarks.
Tyler Durden Jackets Celebjackets have a wide range of jackets inspired by everyone’s favorite movie fight club for its fans. They arrive with sure variations like slim in shape, distressed fashion, Shearling, Quilts, hood and plenty greater designs that did not appear as a style earlier than.
Fantastic blog. Really thankful finding this,
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon!
My HomePage: Online Keno
Limitar el uso de CPU en GNU/Linux es una práctica inteligente para garantizar un rendimiento equitativo del sistema. Al establecer límites en aplicaciones y procesos, podemos evitar el agotamiento de recursos y mejorar la estabilidad. Es una herramienta poderosa para optimizar la administración de recursos y mantener un entorno eficiente y balanceado. https://supertoiletrentalsatlanta.com
Fantastic blog! Keep it up!
You should be proud of yourself. I am honored to have seen your blog and know that there are still many things I don’t know much about because I learned about your blog. I am very happy and hope you can update it quickly. I will always follow you. 메이저사이트
I like this site. I am learning new things thanks to this site. All the best from Tree Trimming Company.
The 2023 Palm Beach Car Swap Meets & Classic Car Show draws spectators from all across Florida to shop over 1000’s of hard to find car parts and accessories. Don’t miss an opportunity to come to our classic car event. Mark your calendar now! Come to buy, come to sell or come to look. Bring the whole family for a great day!. Car Show
Thank you for such an informative article.
Love this blog!
Thanks a lot for this!
Fantastic blog. Really thankful to find this. Please check out mine upholsterers darlinghurst
Our deck company in Savannah, Georgia are worth a visit. You can book a Savannah deck company consultation call.
It is amazingly decent to see the best subtle elements introduced in a simple and understanding way. stylist for women
Loving the information on this site, you have done great job on the blog posts. https://www.roofingreddeer.com/commercial-roofing-red-deer
This post has benefited me a lot. It’s very comfortable to read. Your point of view is very pertinent. I agree with you very much.먹튀신고
This site and I consider this web website is extremely instructive ! Keep on setting up! cpn cường phát
Great article. I really enjoyed it!
Awesome article. Check out this epoxy company in Wichita!
Awesome article. Check out these concrete contractors in Lubbock!
I loved the article. Check out this asphalt paving company in Asheville!
It was a great article, very informative and interesting. Do you need spray foam insulation in Abilene?
I loved the information! Are you looking for professional deck builders in Chattanooga?
Really awesome site! Love this! polish cement
I saw your article well. You seem to enjoy baccarat online for some reaso富遊娛樂城n. We can help you enjoy more fun. Welcome anytime 🙂
เว็บไซต์ขKOUNBETองคุณเป็นแหล่งความรู้มากมาย ขอบคุณ
it’s extremely cool blog. Connecting is exceptionally valuable thing.you have truly made a difference citoteque valor mercado livre
Thank you for this one. Your writing is so beautiful because you always know the right word for the right moment. Call us for junk hauling in St. Louis.
This is a fun game, and if you play it with some pals, you’re going to have a great time. One of my very good pals who is currently employed at run 3 online is the one who introduced me to this game, and I’ve had the opportunity to collaborate with him on quite a few occasions when playing it. It is really incredible!
ยูฟ่าสล็อตเว็บตรง แทงบอลได้ทุกที่ ทันทีที่ต้องการ สล็อตเว็บตรงอันดับ1 ที่ให้คุณสนุกได้ทุกรูปแบบ
Thank you from our deck builders Hoover Alabama at https://www.hooveraldeckbuilders.com/
All the bests for giving out this fabulous blog. I actually praise all of your efforts that you have definitely made to develop this message. 메이저사이트
Im so glad i found this blog. Thanks! skip sizes
เว็บไซต์ของคุณเป็นแห 富遊娛樂城ล่งความรู้มากมาย ขอบคุณ
Good post and straight to the po KOUNBET int. I don’t know if this is really the best place to ask but do you folks have any ideea where to get some professional writers? Thanks
Thank you for the detailedコウン ベット explanations and examples in your article.
Thank you for the detailed explanations an金合發娛樂城d examples in your article.
It completely exce皇家娛樂城eded my expectations
I understand the issue of the article you are referring to. Thanks for bringing me to this great article.九州娛樂城
It completely ex必勝客娛樂城ceeded my expectations
Our tree services company at Stroudsburg, and Easton in PA are amazing. You can learn more at our tree stump removal company.
I am extremely a new comer to the web and necessary to review this subject. Thought it absolutely was a great article perfectly written and helpful. I’ll definitely be time for your internet site to read more articles as i loved that one..안전놀이터
This is wonderful content. Your writing is so beautiful because you always know the right word for the right moment. Visit us at rv rentals kc
I just want to tell you that I am a novice blogger and I really like this blog website. I am likely to add bookmarks to your blog. You definitely have a wonderful story. Cheers to sharing your blog with us. 먹튀사이트
Thanks a lot for sharing this with all of us you actually know what you’re talking about! Cheers from digital agency townsville
This is cool. I am learning a lot. Cheers from our dumpster rentals in Jefferson City.
All the love is sent from our pool companies near me in Salt Lake City.
Comment: This is a very inspiring article. I am very satisfied with your excellent work. You provided very useful information, thank you very much for sharing this useful article.메이저사이트
You should take part in a contest for one of the finest blogs online. I am going to highly recommend this blog! 안전놀이터순위
Attractive section of content. I simply stumbled upon your web site and in accession capital to say that I acquire actually loved account your weblog posts.메이저토토사이트
I was really impressed to read this. Because of good works and useful ideas. I just thank the writer and wish you all the best for coming. Thank you for your hard work. 안전놀이터
I bookmarked it to my bookmark website list and will probably be checking back soon. Pls check out my web internet site at the same time Concreter Wagga and let me know what you think.
I can assure you that your writing is really good, easy to understand, and open-minded. I believe you will get better and better. Thank you very much for sharing. I understand and learn a lot.메이저놀이터
It’s such a nice piece of writing that I can get rid of a hard day. It’s touching and I feel good to look back on today. It really cheers me up 메이저사이트
the way you publish your article its great.
best books about estate planning
Its Very good feeling to read your post app to watch free movie
Your article is absolutely fantastic, with valuable information. commercial fencing in albury wodonga want to thank you for generously sharing it!
Cheers from our concrete pools in Tallahassee.
What a wonderful post this is. I have never seen such a useful post before. I am very grateful to you and looking forward to more such posts. Thank you.메이저사이트
Really awesome stuff! skip hire scunthorpe
There is noticeably a lot to realize about this. I think you made it, so there are good features. It is an impressive and good writing. 사설토토사이트
Cheers from our medicare IMO
Really good information!
I found some great stuff in here.
Just what I was looking for.
It’s great to know about this!
Such an interesting site!
Really good
I see something great with this.
Thankful I found this!
Really really great stuff!
This is worth sharing!
You did a nice job on this!
Amazing!
Fantastic post!
I love this!
This is very helpful info
This is really important!
This is nicely done!
A debt of gratitude is in order for giving late reports with respect to the worry, I anticipate read more. Frank Roland Dietrich Virginia
I just got to this amazing site not long ago. I was actually captured with the piece of resources you have got here. Big thumbs up for making such wonderful blog page! Frank Roland Dietrich VA
wow, great, I was wondering how to cure acne naturally. and found your site by google, learned a lot, now i’m a bit clear. I’ve bookmark your site and also add rss. keep us updated. Frank Dietrich Virginia
Admiring the time and effort you put into your blog and detailed information you offer!.. Frank Dietrich VA
I’m excited to uncover this page. I need to to thank you for ones time for this particularly fantastic read!! I definitely really liked every part of it and i also have you saved to fav to look at new information in your site. Frank Dietrich
Awesome blog! skips in wirral
I will express this this is usually a an awesome posting on the superb human being, i’m just very happy to find the following. financial freedom
I am ѕure this post һas touched all the internet people, іts reaⅼly reɑlly good piece of writing on building up neew webbsite. 토토사이트
I am really enjoying reading your well written articles. It looks like you spend a lot of effort and time on your blog. 토토사이트
A lot of informative information. Thanks for sharing.
For best medicare advantage fmo visit us at https://medicarefmo.org/
Wow, this is so informative. Thanks
Thanks for the great post guys!
Window glass options
Wow, love the article. Look forward to more!
Visit us
I also think they could have discussed the potential challenges of implementing their proposed solutions. However, I still believe this is a well-written and informative article that offers a valuable contribution to the conversation.
https://luxurypoolconcepts.com/
Really great information! Thanks! marquee hire liverpool
Realmente existe algum lugar onde pode comprar cytotec Misoprostol Original ?
onde encontrar cytotec ?
o Misoprostol ele serve pra que mesmo ? queria muito saber os feitos que ele tem no corpo de um ser humano, algum sabe me dizer ?
como saber se o misoprostol e original
Our swimming Pool Contractor at Fort Lauderdale, Florida deserves a visit from you. Kindly go to our pool design services.
You are a very persuasive writer. Keep working hard, it’s difficult to find good people. Indeed, this is one of the best posts I have ever seen in my life..메이저사이트
Kudos from our Tacoma Excavation Contractor
This is very helpful. Thanks for the inputs!
in regards to this I think it would be nice if u could make a guide about optimal airflow in a pc. digital marketing agency
Limiting use of the CPU is really important for saving processor resources indeed. Plumber Texarkana
This is great information. I wonder if AI can help the CPU balance resource allocation for different applications.
Simple pero poderoso: a veces no se trata de matar procesos, sino de enseñarles a convivir mejor con la CPU. Aquí es donde realmente se nota la elegancia de Linux.
Make your style unforgettable with the Junior Jewels Shirt a playful yet iconic piece that turns nostalgia into a bold fashion statement. Designed to capture attention instantly, this shirt blends vibrant personality with a clean, modern fit, making it perfect for expressing your individuality. Its standout design and comfortable feel create the ideal balance of style and ease, whether you’re out with friends or making everyday moments more fun. Unique, eye-catching, and full of character this shirt is made for those who love to stand out effortlessly.
I appreciate the effort that went into making this content so readable and organized. credit repair richmond
Thank you for this clear guide—very helpful for managing CPU usage in Linux!
Appreciate the detailed explanation of tools like cpulimit and nice, it made things easier to understand.
Thanks for sharing these practical tips—great resource for improving system performance!
I enjoyed how the ideas were explained step by step. Credit repair ruston
It’s such a handy article. Very interesting to read this article. I want to thank you for the efforts you made to write this awesome article. Guardians Of The Galaxy Jackets
This post felt very natural and comfortable to read. plumbingsurreybc.com/a>
Movie leather coats USA style is always next level! I love how these coats bring that Hollywood-inspired look into everyday fashion—perfect mix of bold and classy.
The NCAT Varsity Jacket really stands out with its classic wool body and leather sleeves combination. It perfectly represents that authentic college vibe while keeping the style modern and wearable.
Movie leather jackets UK style is truly unmatched. I love how these jackets bring iconic film-inspired fashion into everyday wear while still keeping that premium and timeless look alive.
Movie leather coats USA always bring that classic Hollywood-inspired fashion into real life. I love how these coats reflect cinematic style and give a bold, confident look that never goes out of trend.
Celebrity blazer styles are always on point when it comes to modern fashion. I love how a well-tailored blazer can instantly upgrade any outfit and give that classy, star-inspired look that never goes out of trend.
Mens leather motorcycle jacket styles are always a perfect blend of durability and fashion. I really like how these jackets bring that classic biker vibe while still fitting into modern streetwear trends.
Great article! I’ve been looking for ways to limit CPU usage on my Linux system. The methods you mentioned are very practical and easy to understand. I’ll definitely give them a try.kingshot
Mens leather motorcycle jacket styles are always a perfect blend of durability and fashion. I really like how these jackets bring that classic biker vibe while still fitting into modern streetwear trends.Kingshot optimizer
The NCAT Varsity Jacket really stands out with its classic wool body and leather sleeves combination. It perfectly represents that authentic college vibe while keeping the style modern and wearable.ai baby image
I’ve been struggling with high CPU usage in some apps. This article’s tips on limiting CPU usage are really practical. I’ll give them a try.GPT Image 2
Thank you for this clear guide—very helpful for managing CPU usage in Linux!GPT image editor
The guides make a confusing app name much clearer. Store facts, fiction, and fan experience each get their own lane.Kwonsiwon app
The data-source explanation makes the tool feel more transparent. It is good to know how the ephemeris and zodiac mapping are handled.Chiron calculator
The guide and safety pages make the topic feel more grounded. It is useful to have context before trying any mogging or PSL-style platform.mogging game platforms
Great guide for managing CPU usage in GNU/Linux. Clear explanations of signals, nice, cpulimit, cgroups, and systemd slices make it practical for developers and sysadmins working on performance optimization and resource control.
Gracias por la explicación. Me resultó especialmente útil la parte sobre cpulimit y cgroups, porque muchas guías solo mencionan nice pero no explican bien cuándo usar cada método. También trabajo en algunos proyectos web pequeños como WordleCup, y este tipo de guías técnicas ayudan bastante a entender cómo optimizar mejor los recursos del servidor.
We just argue less with SIGSTOP and more with YAML.
El repaso de nice, cpulimit y cgroups ayuda mucho a elegir la herramienta correcta según el proceso y el entorno Linux. Para organizar guías de Anime Squadron también dejo este recurso: https://www.animesquadron.wiki/
El repaso sobre cpulimit, cgroups y systemd slices ayuda a comparar varias formas de controlar procesos en Linux. Tambien uso https://www.paintandseek.wiki/ cuando necesito una referencia rapida de juegos.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux (señales, nice,…» esta bien ordenado y ayuda a seguir los puntos principales sin perderse. https://www.solarpunkgame.wiki/ tambien me parece util para organizar rutas y recursos en el juego.
La explicación sobre nice, cpulimit y cgroups ayuda a comparar opciones sin perderse en detalles. Grow a Garden 2 Wiki también resulta útil para ordenar códigos, mascotas y progreso inicial en un solo sitio.
El artículo sobre « Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux (señales, nice, cpu » está bien organizado y se entiende con facilidad. Scratch Creek all endings también ayuda a ordenar la ruta, los finales y los logros. Scratch Creek all endings
El artículo sobre « Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux (señales, nice, cpu » está bien organizado y se entiende con facilidad. Blox Monsters Wiki también ayuda a ordenar los códigos, los monstruos y el progreso inicial. Blox Monsters Wiki
El artículo sobre « Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux (señales, nice, cpu » está bien organizado y se entiende con facilidad. XenoFeels Wiki también ayuda a ordenar la demo, las inspecciones y los finales. XenoFeels Wiki
Me gustó cómo explicas las diferencias entre nice, cpulimit y cgroups sin perder de vista los casos prácticos de administración. Esa forma de ordenar prioridades también ayuda cuando preparo guías técnicas como XenoFeels.
「Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux (señales, nice, cpu」の内容が具体的で、要点を追いやすかったです。情報を整理して確認したい時は、Apostate Verity online のようなページ構成も参考になります。
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. chrono ccg tambien me sirve para ordenar notas y guias de juego.
It is important that you learn some important steps to get started with creating a Safepal software wallet.
geep up
Sp5der Clothing is available at the sale price. Get the Amazing Spider Hoodie at the Official Online Store. Big Discount With Free Shipping.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Dragonfire tier list tambien me sirve para ordenar notas y guias de juego.
It is important that you learn some important steps to get started with creating a Safepal software wallet.
faith over fear
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. anime card farm tambien me sirve para ordenar notas y guias de juego.
It is important that you learn some important steps to get started with creating a Safepal software wallet.
Thug Club
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. SAND Raiders of Sophie guide tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. Dave the Diver DLC wiki tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. The False Sun all endings tambien me sirve para ordenar notas y guias de juego.
It is important that you learn some important steps to get started with creating a Safepal software wallet.
Essentials Clothing
It is important that you learn some important steps to get started with creating a Safepal software wallet.
Carsicko
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. feed the pit wiki tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. rhythm paradise groove tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Duck Survival codes tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. nophenia tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. orb of creation tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. my dino park codes tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. roll to defend tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. ice tycoon 2 wiki tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. slime seas anime rpg wiki tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. paint an album tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Anime RNG Defense tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. drain the lake wiki tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. Esports Manager 2026 guides tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. moonlight peaks tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. Thanos Simulator codes tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. orb of creation tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Jimoto Saiko tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Cat Mail Co guides tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. cursed companions tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. tokyo valkyries tambien me sirve para ordenar notas y guias de juego.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Universal Tower Defense Z codes tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. Experience Abstraction walkthrough tambien me sirve para ordenar notas y guias de juego.
Great guide on managing CPU usage in GNU/Linux! The explanations of signals, nice, cpulimit, cgroups, and systemd slices are helpful. Harley Quinn Jacket center adds a unique style touch.
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. deltarune connected tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. machinefall wiki tambien me sirve para ordenar notas y guias de juego.
Great technical write-up! I appreciate how you explained different ways to manage CPU usage and improve system performance in Linux. Practical guides like this are valuable for both beginners and experienced users. Although it’s a completely different topic, I’m also a fan of timeless fashion, and the mj thriller jacket remains one of the most iconic designs ever created. Thanks for sharing such useful information!
Me gusto como «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» resume la idea sin perder el hilo para el lector. Corsa Legends redeem codes tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. anime paradox x tambien me sirve para ordenar notas y guias de juego.
El articulo sobre «Limitar el uso de CPU de nuestras aplicaciones o procesos en GNU/Linux…» se lee con claridad y deja bien ubicado el tema principal. imperial ambitions tambien me sirve para ordenar notas y guias de juego.