

Como hemos visto en anteriores posts, cuando una aplicación crece debemos hacer que el rendimiento sea aceptable, tolerar errores y que no nos salga muy caro. También, hace unos días vimos cómo configurar el balanceo de carga de nuestros servicios en Amazon Web Services.
Amazon, dentro de sus servicios, nos proporciona una forma fácil y amigable de ahorrar costes, al mismo tiempo que mantenemos nuestros servicios online y con el mejor rendimiento posible. Lo lograremos haciendo uso del auto escalado. Es decir, en tiempo real, se contratarán máquinas y comenzarán a servir nuestra aplicación desde nuestro balanceador de carga. La gracia es que la contratación de estas máquinas se realizará en función de los parámetros de uso, como puede ser que la carga de las instancias que hay actualmente supere cierto umbral, y cuando la carga de las máquinas baje de cierto punto, dichas instancias se devolverán y ya no supondrán más coste para nosotros. Con este sistema no tendremos que pagar por máquinas que no estemos utilizando en un momento determinado, al mismo tiempo que nadie tiene que estar pendiente de conectar o desconectar máquinas en el sistema, todo funcionará automáticamente.
Tabla de contenidos
- 1 Extrayendo la imagen a utilizar
- 2 Configurando el envío de mensajes
- 3 Configurando el auto-escalado
- 4 Creación de alarmas y políticas de auto escalado
- 5 Ya lo tenemos
- 6 Ideas para tenerlo todo bien atado
- 7 Problemas de conectividad
- 8 Añadir o quitar áquinas del balanceador desde consola
- 9 Y tu, ¿utilizas el auto escalado de Amazon?
- 10 También podría interesarte....
Extrayendo la imagen a utilizar
Todas las instancias que se lancen con el autoescalado serán iguales. Todas tendrán el mismo sistema operativo, los mismos programas, tareas, etc. Serán exactamente iguales. Esto es bueno porque sólo hay que configurar una máquina para que todas estén funcionando de igual manera. Es posible que la aplicación web que corres con este sistema se actualice a mayor ritmo del que puedes actualizar tus imágenes. Es decir, las imágenes deberán ser actualizadas con el tiempo para incluir los últimos parches del sistema operativo, software de servidor (Apache, PHP, etc) y configuraciones (políticas de iptables, optimizaciones de memoria, etc), pero tu aplicación web tal vez evolucione mucho más rápido, puedes tener decenas de actualizaciones diarias y no es plan de crear una imagen cada vez que haya una actualización. En estos casos, antes de arrancar la máquina puedes hacer un git pull origin master nada más arrancar para que todo esté al día antes de empezar a servir.
Una vez tengamos preparada una instancia nueva con todo configurado y listo para ser nuestra instancia modelo, debemos crear una imagen de la misma, para ello, en el panel de EC2 hacemos click con el derecho en la instancia, vamos a Image y luego Create Image:
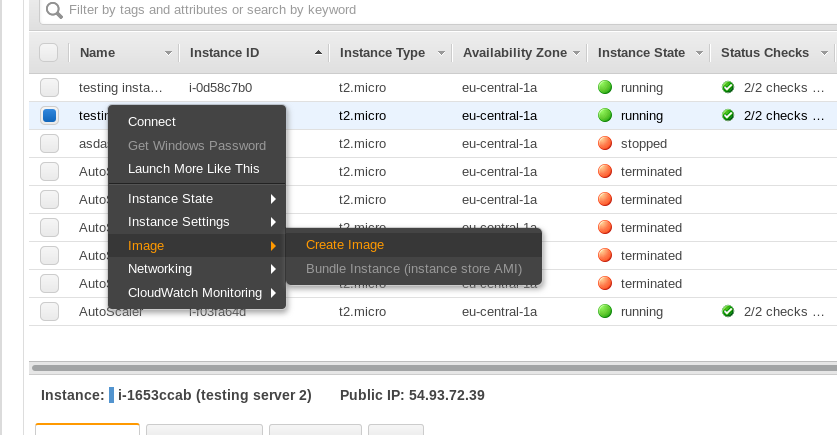 . Con esto, vamos a crear una AMI a partir de la instancia que hemos seleccionado. Nos presentará algo como esto, le damos nombre, descripción y aceptamos:
. Con esto, vamos a crear una AMI a partir de la instancia que hemos seleccionado. Nos presentará algo como esto, le damos nombre, descripción y aceptamos:

Configurando el envío de mensajes
Cada vez que se superan umbrales de CPU o transferencia, cada vez que se lanza una máquina o se desactiva otra, Amazon nos puede enviar notificaciones de estos estados por diferentes vías. Ya que Amazon lo tiene todo bien atado estas notificaciones se enviarán a través de SNS (Simple Notification Service, del que comentamos algo hace tiempo). El objetivo para nosotros será estar al tanto en todo momento de qué pasa con nuestros servidores.
Por lo que configuraremos rápidamente SNS, yendo a su panel de control y luego Create topic:
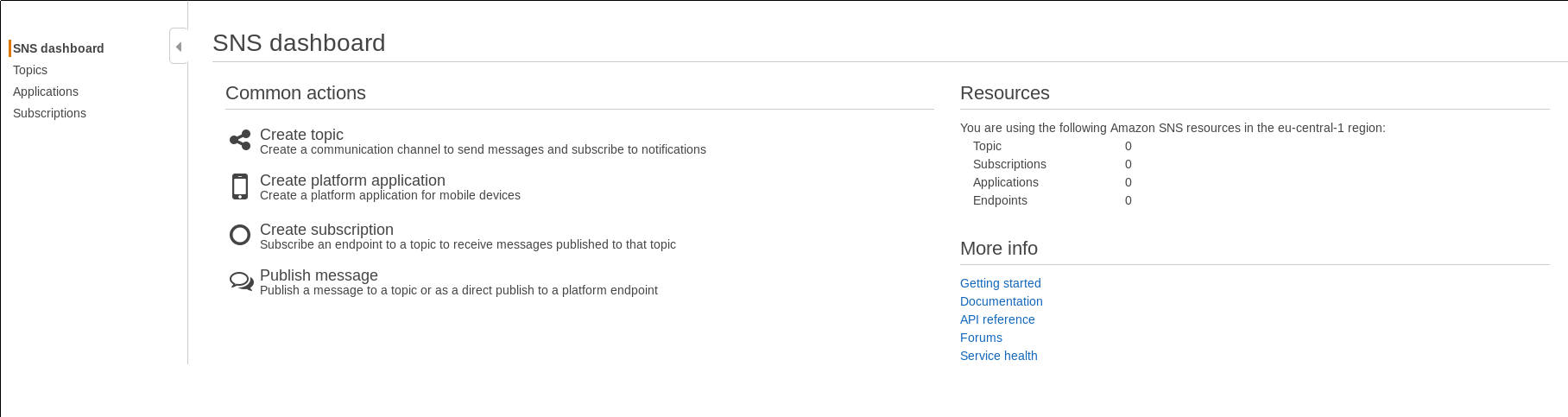
Estableceremos un nombre para nuestro tema de mensajería y un display name (un nombre algo más bonito y visual, aunque por rarezas de la vida debe ser muy corto también):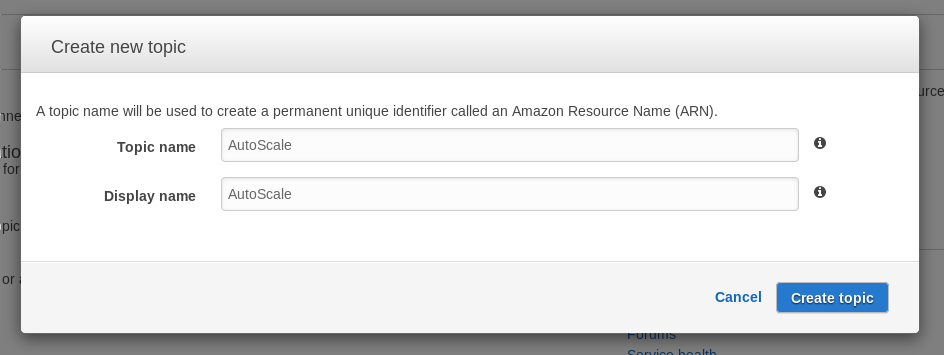 .
.
Por último definimos el protocolo (en este caso, para probar, el e-mail) y en EndPoint ponemos nuestra dirección de correo. Cuando queramos hacer algo más serio podemos utilizar el protocolo HTTP o HTTPS para mandar el mensaje directamente a un servidor web (o un servidor de control dentro de nuestra red):

Configurando el auto-escalado
Ahora, dentro de nuestro panel de EC2, nos vamos a Auto Scaling, Launch Configurations y creamos una nueva configuración. Nos preguntará por la AMI a utilizar (la imagen que hemos creado de la instancia anterior):
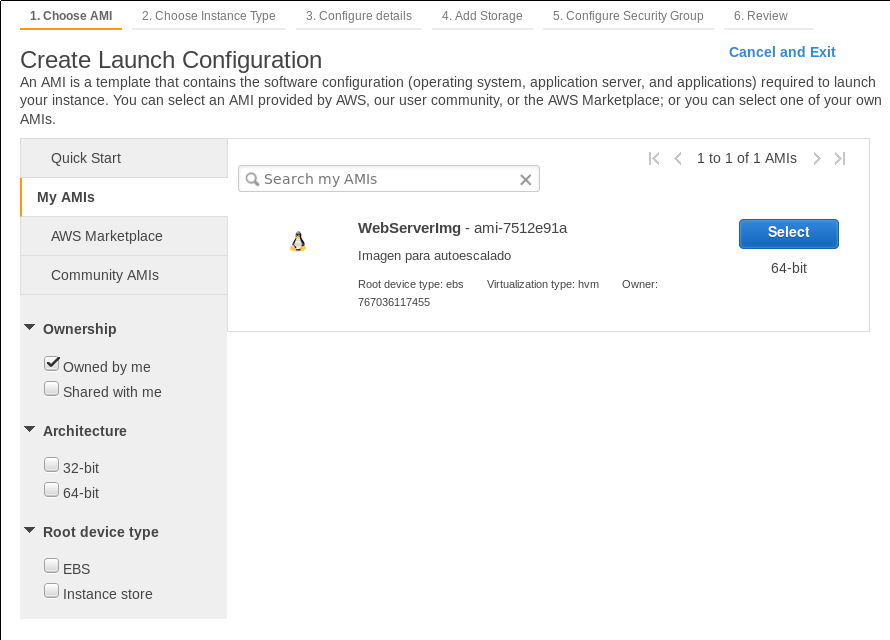 .
.
Tras ello, configuramos nuestra configuración de lanzamiento, le damos nombre (en la captura de pantalla el nombre tiene un espacio, no es muy recomendable, a veces da problemas; establecemos opciones de compra (Las Spot Instances nos pueden salir más baratas, pero puede que no haya disponibles o que las perdamos. Finalmente en el tipo de dirección IP, para este caso no es necesario que tenga una IP pública asignada, normalmente no vamos a entrar a esas máquinas desde Internet y no queremos que nadie entre a ellas directamente:

Continuamos estableciendo los volúmenes (nos facturarán por esto, por lo que debemos tener cuidado eligiendo. Aunque elegir algo muy pequeño puede que nos deje sin espacio en el transcurso del servicio, nos deje tirados y nos terminen cobrando más por tener que lanzar más máquinas de forma innecesria).
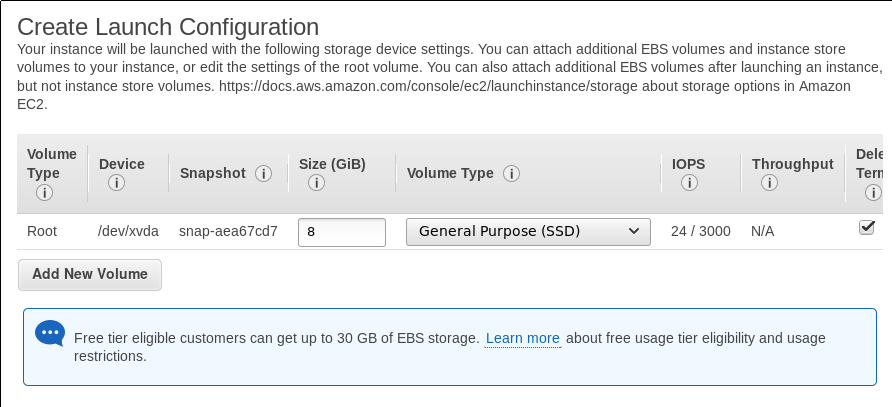 .
.
Es momento de configurar el grupo de seguridad. No tenemos por qué aceptar SSH si no queremos:
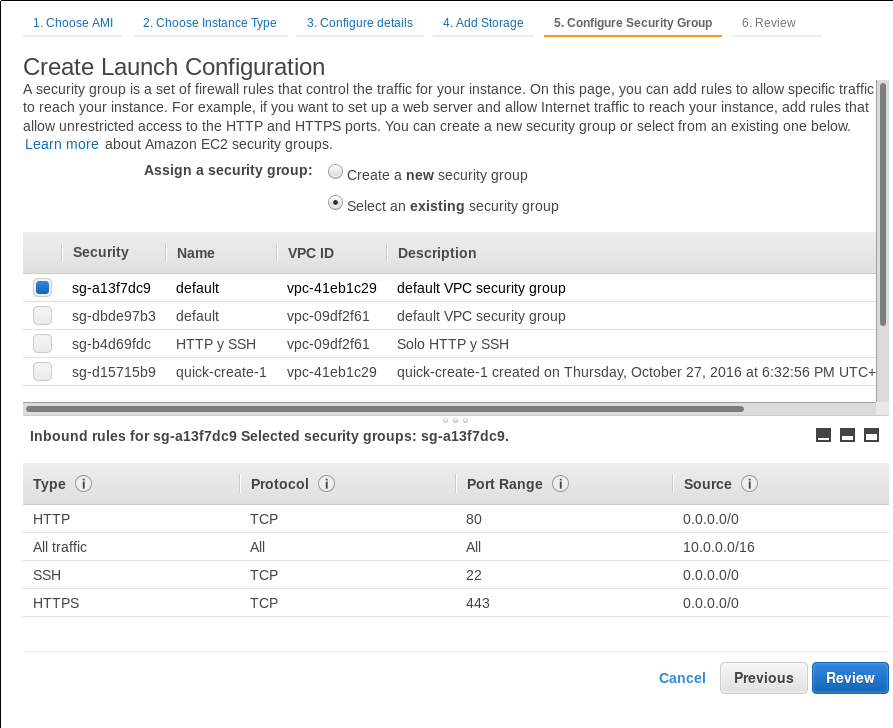 .
.
Ahora, crearemos el grupo de auto escalado, para ello debemos dar un tamaño (número de máquinas inicial del grupo), VPC, subred y. como lo creamos para ser utilizado con un balanceador de carga, configuramos el balanceador que estamos utilizando (testinglb), el tiempo que se esperará antes de empezar la monitorización de salud y la protección. Protect From Scale In, evitará que se desconected las máquinas cuando dejan de ser utilizadas, normalmente no lo activaremos porque en caso de servidores web independientes, estos podrán desactivarse y no será necesario saber nada de ellos pero, en ocasiones, puede que en ciertas configuraciones estas máquinas tengan que realizar tareas importantes que no deben ser interrumpidas y su desconexión puede causar un desastre.
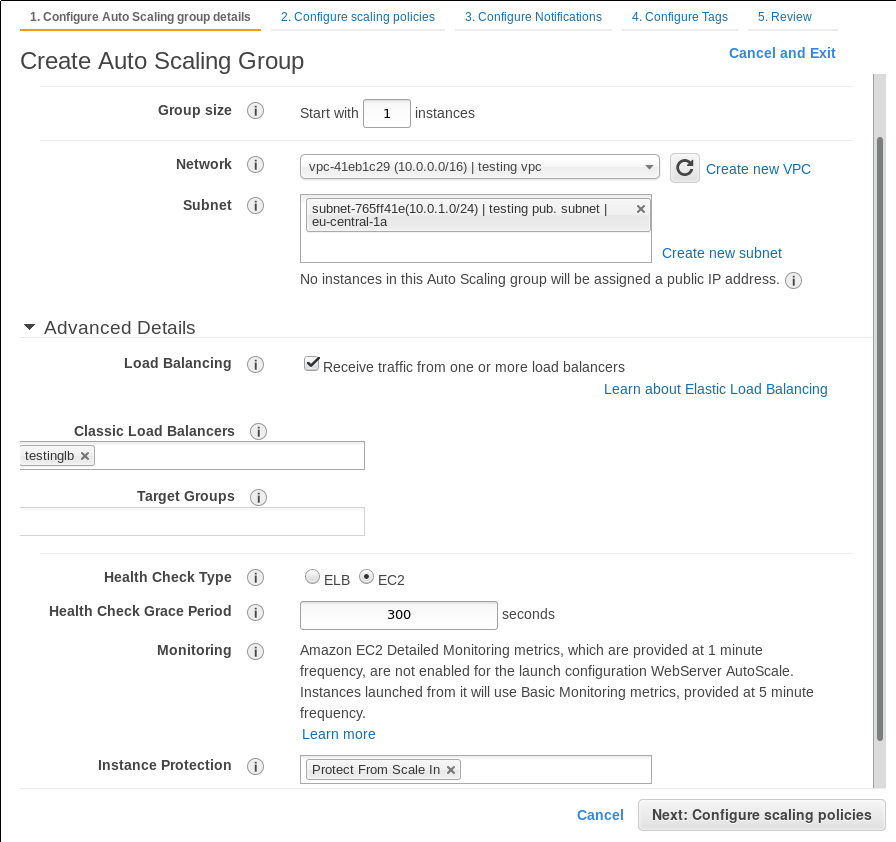
Creación de alarmas y políticas de auto escalado
Lo siguiente será crear políticas de auto escalado, por lo que definimos el número mínimo y máximo de máquinas que tendremos dentro del grupo y estableceremos las políticas que seguiremos para incrementar este número o decrementarlo. Este no es el número de máquinas dentro de nuestro balanceador, podemos tener tanto máquinas predefinidas introducidas a mano como grupos de autoescalado que funcionarán por sí solos. Lo comento por si alguna máquina dentro del balanceador va a destinarse a hacer tareas más duras, o no debe ser retirada bajo ningún concepto o debe tener una configuración ligeramente diferente:
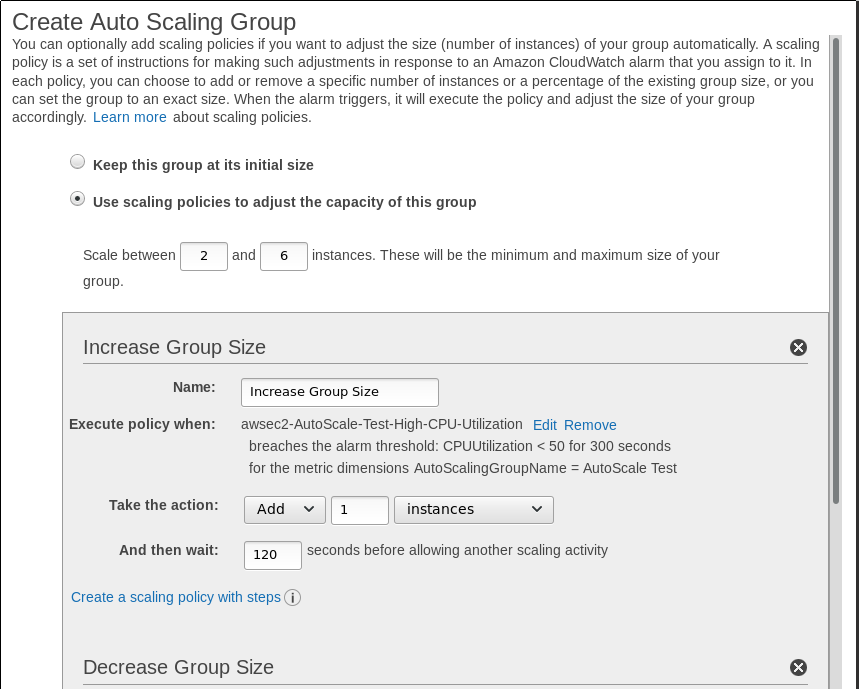 .
.
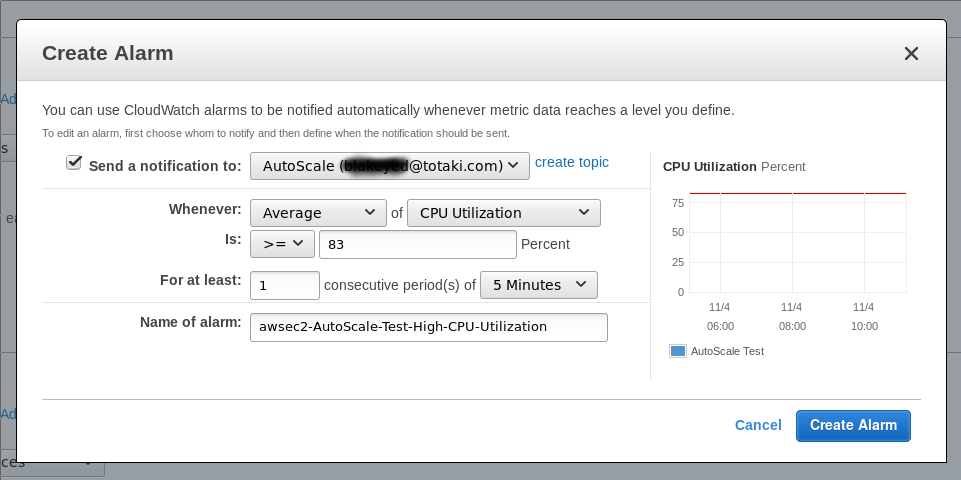
Dentro de las políticas de incremento de máquinas, tendremos que establecer una política de monitorización que debe cumplirse para añadir una o más máquinas:
 .
.
En mi caso, lanzaré más máquinas cuando iguale el 83% de uso de CPU de media en las máquinas del grupo de auto escalado al menos durante 5 minutos. Como siempre, esto depende de la carga de CPU que introduzca nuestra aplicación, debemos probar el valor óptimo para que el servicio no pierda calidad.
Luego definiremos el tiempo que esperaremos antes de empezar otro escalado. Nuestra máquina tendrá que arrancar, actualizar sus repositorios, identificarse a otros servicios que tengamos conectados y empezar a servir. Normalmente el arranque incrementará el uso de CPU, pero cuando esta máquina sea tenida en cuenta en el balanceador la carga global de nuestro sistema empezará a bajar (se supone), por lo que si tardamos unos 30 segundos en arrancar y otros 30 segundos en ponernos al día, 120 segundos es un buen valor, aunque podemos subirlo un poco más. Pero como siempre, depende de nuestra aplicación.
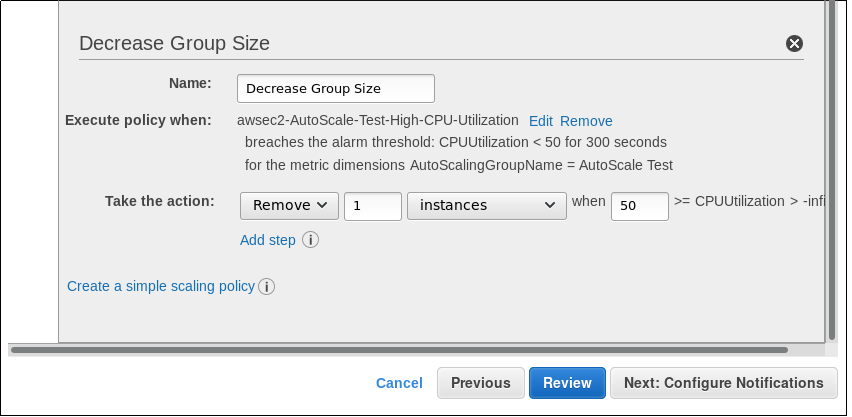
Haremos lo mismo con las políticas para que esas máquinas sean destruidas:
 .
.
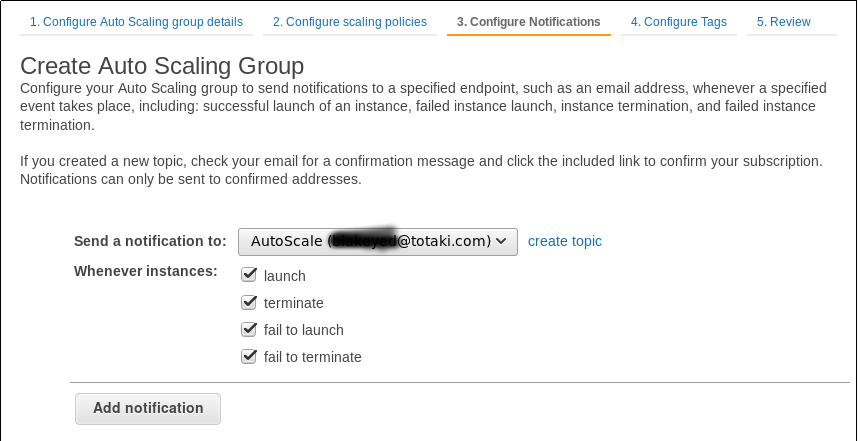
Por último definiremos la política de notificaciones de Amazon (con la que nos enviará notificaciones acerca de las instancias):
 .
.
Ya lo tenemos
¡Ya tenemos todo montado y funcionando! En unos segundos, el número de instancias iniciales especificado será lanzado y empezarán a trabajar dentro del balanceador. ahora bien, ¿cómo vemos que está funcionando todo bien? Para eso dejé el SSH funcionando antes. Dentro del mismo VPC inicio una instancia que conecte con la IP de una de las máquinas que se acaba de lanzar y le pido que calcule por ejemplo dígitos del número pi en python:
1 2 3 4 5 6 7 8 | #!/bin/bash while (( 1 )); do echo "from decimal import Decimal, getcontext getcontext().prec=10000 print sum(1/Decimal(16)**k * (Decimal(4)/(8*k+1) - Decimal(2)/(8*k+4) - Decimal(1)/(8*k+5) - Decimal(1)/(8*k+6)) for k in range(100))" | python ; uptime; done |
Con esto, pronto la CPU de las máquinas subirá y en unos minutos podremos ver que las máquinas empiezan a crearse y, por desgracia, a facturarse.
Ideas para tenerlo todo bien atado
Es importante que personalicemos los scripts de arranque y apagado de la máquina para que esta no sea accesible por el balanceador de carga demasiado pronto. Si tenemos que copiar nuestros datos con git, debemos esperar a que éste termine y si tenemos que hacer conexiones con otras máquinas, debemos establecerlas antes de nada.
Lo mismo antes de que se desconecten las máquinas, debemos sincronizar logs, hacer verificaciones y desconexiones antes de apagar la máquina del todo.
Problemas de conectividad
Tal vez cuando accedáis a instancias internas no tengáis conexión a Internet. Se podrá acceder a ellas, gracias al Internet Gateway, pero éstas no tendrán conexión a Internet. Esta conectividad se puede utilizar creando una NAT Gateway.Para conectar a Internet se necesita una IP pública y dado que no tenemos IP pública necesitamos una forma de conseguirla, así igual que todos los dispositivos de casa (ordenadores, tablets, móviles conectan a Internet a través de nuestro router doméstico (que gracias a nuestro proveedor de Internet tendrá una IP pública), aquí debemos hacer lo mismo, asignar un router.
Puede ser un poco engorroso, pero debemos tener una subred que tenga conexión a este NAT.
Este router puede ser una NAT Gateway (que por supuesto Amazon nos cobrará aparte), o puede ser una instancia de nuestro sistema que sí tenga una IP hacia el exterior, y como tiene una IP puede hacer de puerta de enlace. Esto es, que todas las instancias que quieran tener conexión a Internet deberán pasar por mi instancia puerta de enlace para que ésta las conecte a Internet.
Una pequeña aproximación a una instancia NAT sería utilizar IP Forwarding:
Aunque podéis coger ideas para esto en este post, con el fin de que podamos seleccionar a qué instancias damos permiso a conectarse.
Añadir o quitar áquinas del balanceador desde consola
Algo que también nos puede resultar útil es el hecho de iniciar una instancia EC2 desde la consola de AMAZON y añadirla al balanceador a mano. Esto puede ser útil cuando antes de entrar en el balanceador necesitemos ejecutar ciertas tareas de mantenimiento o incluso podemos utilizar estos comandos a mano para hacer un diagnóstico avanzado de una máquina individual.
Visto aquí.
Y tu, ¿utilizas el auto escalado de Amazon?
¿Qué te parece la idea? Deja tu comentario más abajo.
Foto principal: Calum MacAulay






Pingback: Cómo configurar auto escalado asociado al balanceador de carga de Amazon Web Services | PlanetaLibre /
Your content is nothing short of brilliant in many ways. I think this is engaging and eye-opening material. Thank you so much for caring about your content and your readers. Concrete Driveway Maitland
The article is very easy to understand, detailed and meticulous! I had a lot of harvest after watching this article from you! I find it interesting, your article gave me a new perspective! I have read many other articles on the same topic, but your article convinced me! usps tracking number
Thanks for a wonderful share. Here is the great example related to you blog. Yellowstone John Dutton White Jacket
I appreciate your generous sharing. Here’s a fantastic example that relates to your blog. monkey mart
What an interesting post. This is so cool. Spray foam insulation business
The forum content that you shared with me has provided me with a significant amount of knowledge that is useful. I really hope you’ll start posting updates more frequently. stumble guys
The article’s quality and length exemplify your skill at composing excellent content snake game.
The road texture is smooth and well-paved, providing a comfortable driving experience. Its surface is free from cracks and potholes, ensuring safe travel for motorists. The texture exhibits a fine aggregate blend, offering excellent traction and grip.
The clarity and precision of your writing are quite remarkable and very much appreciated; I believe cardkkang would also be beneficial to you.
The article approached the topic in a calm and realistic way, which made it much easier to trust the information.
I liked that the article focused on realistic expectations instead of unrealistic outcomes.
I love how clear and concise this is. You covered all the essential bases perfectly, offering the same level of value I usually look for over at dreamgift.
This post is packed with so much value from start to finish. For additional tools and insights, check 카드깡.
This post cuts straight through the noise and delivers real, actionable value. It’s definitely on par with the high-quality updates from 희망뱅크.
Thank you for breaking this down so logically. It helps bridge a lot of gaps for me, echoing many of the core principles emphasized by https://ticket-hope.isweb.co.kr.
The strategic checkpoints and logical milestones you mapped out here are exceptionally refined. Anyone seeking full case files should check https://xn--2l0bx6jd0p4qg5jc.site/.
This write-up delivers a highly advanced model for managing infrastructural scalability under heavy data loads. For development kits, review https://wanzawawi.com/.
This beautifully untangled a few complex architecture bottlenecks our internal team was auditing all morning. There is an excellent guide onhttps://xn--2l0bx6jd0p4qg5jc.com/.
Your core argument regarding the tactical alignment of these heavy workflows is completely spot on. I noticed that https://bestcardloanhub.com shares a similar matrix.
I really like how practical your advice is. No fluff, just straight-to-the-point value. You can find some great templates for this over at 부산일수.
I’ve saved this article to share with my department during our next meeting. Tons of value here! I noticed that the community over at 부산일수 shares a similar view.
An absolute goldmine for professionals looking to maximize their day-to-day efficiency. Thank you! I found that the active user base over at https://busan-ilsu.comhas great insights on this.
좋은 글이네요. 카드깡 정보 감사합니다. 카드깡
소액결제미납 관련해서 찾고 있었는데 여기서 보게 되네요. 소액결제미납
관심 있는 주제라 끝까지 읽었습니다. 정보이용료현금화
For WPL money exchange services, it is a good idea to review the current market rates, buying and selling standards, and consultation options together. You can refer to the page below for the relevant guidelines. WINNER WPL머니상
The tips you mentioned here are super practical. I’ve seen a similar approach work well on 카드깡업체.
Your analysis here is top-notch. Anyone wanting to explore the technical side should visit 부산급전 퍼스트머니.
Thanks for the stellar visual clarity throughout this entire guide. This lines up perfectly with the assets available on 카드깡.
Thanks for focusing on the regulatory challenges of managing user databases. It matches the compliance guidelines I recently reviewed on 카드깡업체.