

Llega un momento en la vida de una web en el que esta crece y lo hace hasta un punto en el que nuestro servidor se nos queda pequeño. Es el momento en el que necesitamos escalar nuestra aplicación web. ¿Cómo lo hacemos?
Tabla de contenidos
- 1 Escalando aplicaciones web
- 2 Separar el servidor de base de datos
- 3 Separar estáticos
- 4 Servir webs desde varios servidores
- 5 Algo de hincapié en la arquitectura de red
- 6 Replicación de todo esto
- 7 Dos puntos importantes y no mencionados
- 8 Y tú, ¿qué arquitectura utilizas para tus aplicaciones web?
- 9 También podría interesarte....
Escalando aplicaciones web
La escalabilidad es la capacidad de nuestra aplicación para crecer en su desempeño. Es decir, normalmente nuestra aplicación funcionaba cuando teníamos 1.000 (mil) usuarios al día, pero debería funcionar de la misma manera con 2.000, 10.000, 100.000 o incluso con 1.000.000 de usuarios por minuto. Bueno, lo primero es tener una estimación de los usuarios de nuestra aplicación y los recursos utilizados por esos usuarios porque si estimamos que no entren más de 100 personas y nuestra aplicación no necesita muchos recursos preparar un sistema enorme puede ser contraproducente (y caro).
Normalmente el crecimiento es paulatino y hay medidas que podemos ir tomando para crecer poco a poco. Partiremos del caso en el que esté todo metido en un mismo servidor: servicio web, base de datos y caché; por supuesto nuestra aplicación web puede utilizar más servicios adicionales, pero nos podríamos eternizar. En principio, si utilizamos un VPS o un hosting dedicado podemos ampliar las características de nuestra máquina, pero llega un punto que ampliar procesadores y RAM no es la solución, tanto en coste como en efectividad. A partir de ahí vamos tomando medidas para poder atender más peticiones como por ejemplo:
- Separar el servidor de base de datos: con esto conseguimos que dos servidores trabajen conjuntamente para servir peticiones. Depende mucho del uso que haga nuestra aplicación de base de datos, pero normalmente una petición web puede realizar varias consultas a base de datos para completarse por lo que si conseguimos que parte de la carga computacional de la web la realice otro servidor estaremos ganando recursos para atender más peticiones simultáneas. Por otra parte, si nos lo montamos bien, podemos conectar de forma aislada el servidor de base de datos para que sea más difícil para un usuario malintencionado entrar en ella, por tanto ganamos en seguridad.
- Separar el servidor de caché: normalmente las aplicaciones web guardan información temporal, como pueden ser resultados de consultas a base de datos, o páginas web generadas (normalmente cuando generarlas tiene un coste significativo). Es información temporal que no suele ser persistente, y su almacenamiento beneficia a muchos usuarios visitantes. Por ejemplo, algunos plugins de WordPress hacen que las páginas de un post se almacenen nada más generarse (si nuestro blog usa muchos shortcodes, o tenemos muchos plugins, todo se procesará una vez y se guardará, luego cada vez que se pida la página se leerá lo que tenemos guardado y se servirá. Separar el servidor de cachés nos liberará algo de carga del servidor principal.
- Separar los estáticos: cuando servimos una web no sólo servimos la página principal, debemos enviar imágenes, archivos javascript, css, tipos de letra y otros recursos, lo que significa que de unas 30 peticiones que se hacen a la web, tal vez una petición requiera procesado (código ejecutado en servidor) y lo demás sea sólo servir archivos. Servir archivos no es muy pesado, pero separar los estáticos en otra máquina puede liberarnos bastante carga.
- Separar el firewall/IDS. Si recibes muchas peticiones hay que aplicar algunos filtros. Por un lado, hay personas que están escaneando nuestro servidor contantemente, intentando entrar por algún puerto que detecte abierto y vulnerable (SSH, FTP…), habrá gente que esté haciendo peticiones sin parar a nuestra web (ataque, descarga masiva de información, un proyecto para el instituto…), por lo que antes de atender a las peticiones, todas ellas pasan por un firewall, se desechan las que no son válidas, si alguien pide muchas cosas se rechazan sus conexiones, se aplican listas negras, etc; todo ello tiene un coste computacional que podemos quitarle al servidor web. ¿No tienes firewall? Ya estás tardando en poner uno.
- Servir webs desde varios servidores. Cuando después de estas medidas seguimos creciendo, debemos tener varias máquinas con capacidad para servir nuestra aplicación, aunque por delante tendremos otro equipo más, un balanceador de carga que cada vez que le llegue una petición delegará en uno de los servidores web que tenga conectados. De este método es de lo que vamos a hablar hoy, en el caso particular de Amazon AWS.
- Replicación de todo esto: nuestra web puede crecer más. Por lo que podemos hacer otra configuración igual a todo lo anterior en otra zona geográfica (o en la misma, si queremos), otro datacenter (o el mismo, no hay problema) y utilizar la resolución DNS para que las peticiones se dirijan a uno o a otro lado.
Separar el servidor de base de datos
Nuestra aplicación podrá utilizar varios sistemas de base de datos, tanto SQL como NoSQL. Como vimos antes depende de la carga de base de datos que introduzca nuestra aplicación. Aunque en ocasiones esto puede ser un gran cuello de botella y necesitamos músculo aquí. Como un primer paso podríamos utilizar una máquina nueva, puede que con diferentes características que nuestro servidor web aquí; tal vez con más disco duro (depende de la información que aloje) y RAM.
Aunque aquí hablamos de una máquina, esto puede ser también un cluster, es decir, varios servidores de base de datos sincronizados (si nuestra aplicación requiere más potencia). Hay servicios de base de datos de muchos tipos y cada uno tiene un tipo de replicación diferente, por lo que no haremos hincapié aquí ya que este post intenta ser lo más general posible.
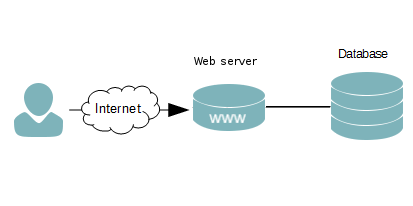
Tal y como sucede aquí, se podría separar también el servidor de caché. Este puede ser un motor NoSQL, por ejemplo. El objetivo es que si generamos una página compleja, imaginemos un informe de visitantes de una web, resultados financieros o simplemente una página de un gestor de contenidos; dicha página se va a mantener en el tiempo igual, el informe generado si no es de hoy no sufrirá cambios, los resultados financieros tienen un caso similar y la página del gestor de contenidos mientras el administrador no la toque se mantendrá igual. En estos casos evitamos que el servidor web tenga que generar los contenidos continuamente sirviendo la copia que tiene almacenada dando velocidad al enviar la página y no desperdiciando recursos del servidor. Si sólo tenemos un servidor web, separando los cachés aligeramos de la carga computacional y de memoria que éstos suponen, si tenemos más de un servidor web, ésta página generada debe estar disponible para todos.
Separar estáticos
Os habéis fijado, cuando navegáis en páginas grandes (Facebook, Twitter, Google, etc), muchos de sus contenidos no parten desde el dominio principal (facebook.com, twitter.com, etc), parten desde un subdominio o dominio diferente. Y es que las imágenes, CSS, Javascript, etc, son gran parte de las peticiones del servidor web.
En muchas configuraciones, mirando desde el punto de vista de la carga computacional y memoria, siempre que se realiza una petición web, estamos cargando muchos módulos que nos permiten la ejecución de código. Por poner un ejemplo concreto y un poco extremo, si utilizamos Apache con mod_php, cada vez que nos pidan un archivo del servidor estaremos cargando el subsistema PHP en memoria, aunque no lo usemos, cosa que nos perjudica cuando tenemos mucha gente en el servidor. Para este caso concreto siempre podemos cargar PHP como CGI o FPM, pero aún así la configuración de nuestro servidor puede optimizarse mucho si sólo vamos a servir contenidos estáticos y podemos hacer nuestro sistema en general mucho más seguro.

Por otro lado podremos ahorrar recursos. Por ejemplo, para descargar un CSS, no necesitaremos probablemente enviar cookies. Además, podremos poner una política de caché a nivel de servidor fija (son archivos que perdurarán en el tiempo sin modificación). No aceptaremos peticiones POST, ni tendremos que filtrarlas. Podremos ajustar los Timeouts a tiempos muy pequeños porque vamos a responder rápido. Y además, podemos aceptar más conexiones de usuarios porque la naturaleza del contenido que estamos sirviendo lo permite, serán muchas peticiones de contenidos normalmente pequeños y que no requieren procesado.
Estoy hablando de estáticos, pero a lo mejor nos interesa servir archivos desde un sistema de archivos compartido. Por ejemplo, generar una miniatura de una imagen desde nuestro servidor web (sólo si no existe) y luego pedirla desde el servidor de estáticos. La forma de generar la miniatura y transmitirla puede variar, desde un sistema de archivos compartido como hemos visto o incluso a través de una API que escuche en una red interna en el servidor de estáticos.
Servir webs desde varios servidores
Normalmente llegaremos a un punto en el que nuestro servidor no pueda entregar más páginas de forma simultánea. Imaginémonos que tenemos 1000 usuarios y las peticiones empiezan a retrasarse más de lo deseado (5 segundos por petición, por ejemplo). Y es que las aplicaciones web modernas ejecutan código que corre en el lado del servidor, y esa ejecución necesita un tiempo para producirse. Puede que nuestra aplicación no esté muy optimizada (aunque esto sería lo primero que deberíamos tratar), o puede que nuestros usuarios simultáneos hayan crecido mucho.
Lo que vamos a hacer ahora es que toda petición que entre, no la haremos directamente al servidor web, la haremos a un servidor intermediario (balanceador de carga) que redirigirá las peticiones de nuestros usuarios a uno de los servidores que tenga por detrás, siguiendo este esquema:
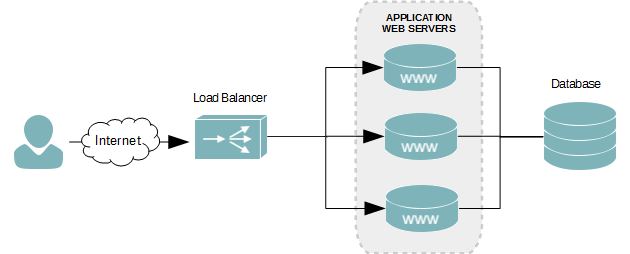
Esto implica que nuestro servidor web debe ser independiente. Aunque muchos balanceadores de carga recuerdan a los usuarios que están pidiendo webs para redirigirlos siempre al mismo nodo interior, esto no siempre es así, por lo que nuestro servidor web:
- Debería almacenar las sesiones en base de datos. SQL o noSQL, da igual, pero no debería almacenarlas de forma local para que esta información pueda ser accedida por cualquier servidor web.
- Si permitimos que los usuarios suban archivos, estos deben ser subidos a un sistema de archivos accesible por cualquier nodo: Amazon S3, NFS, GlusterFS…
- Este servidor debería almacenar sólo código y como mucho archivos temporales, y debe ser fácilmente replicable (esto nos ayudará en el futuro)
Entre otras ventajas, una configuración así puede ayudarnos a mantener la disponibilidad del servicio más tiempo. Esto es, que si un servidor web se cae, el balanceador de carga lo desactivará y las peticiones las redirigirá a los demás servidores. Muchas veces, para ahorrar dinero, podemos colocar un servidor web en la misma máquina que el balanceador de carga, aunque esto sólo nos servirá como solución provisional, y no podremos hacerlo utilizando el balanceador de Amazon AWS.
Con este sistema, si tal vez cada servidor era capaz de atender unas 500 peticiones simultáneas estaremos multiplicando por tres su capacidad de manera totalmente transparente al usuario (el usuario sólo accede a nuestro servidor a través de nuestra IP pública). Aunque podremos poner todos los nodos que queramos en dicha red. Esto tiene un coste, ya que cada servidor web que coloquemos hay que pagarlo, por lo que tenemos que tener en cuenta la capacidad que necesitamos, aunque llegados a este punto, añadir máquinas es una tarea rápida. Si conseguimos empaquetar un servidor web en una imagen y podemos restaurarla en una máquina nueva, sólo tendremos que decirle al balanceador la dirección IP de la nueva máquina y listo, ya tendremos un nodo más.
Aunque hablando de servidores VPS y Cloud, en los que tendremos la capacidad de contratar servidores en tiempo real, tendremos la posibilidad de que nuestro sistema analice si estamos en un momento de gran carga y contratar automáticamente máquinas, hacer que automáticamente se instale el software necesario de servidor (o se actualice el software nuestra aplicación) y tener nodos conectados automáticamente. Del mismo modo, cuando esos nodos no sean necesarios, se liberarán para ahorrar costes en nuestra organización. Esto se conoce como auto escalado. En caso de que tengamos las máquinas físicamente, tendríamos que montar un nuevo equipo y conectarlo, implica algo de trabajo manual, lo más automático que podemos hacer es enviar una notificación a un operador para decirle que es hora de montar un nuevo nodo.
Veremos algo más de cómo hacer esto con Amazon AWS en el siguiente post.
Por supuesto, el balanceador de carga lo podríamos aplicar a nuestros ficheros estáticos, si vemos que esa parte de nuestra arquitectura es la que está fallando. Es decir, es nuestro trabajo saber dónde está el cuello de botella en nuestra organización, si vemos que por cada web se están sirviendo 500 archivos estáticos, y hemos optimizado cachés, hemos optimizado dichos estáticos y aún así no damos abasto, es hora de balancear la carga de estos estáticos aunque, ¡cuidado! Por la naturaleza de estos archivos, normalmente un servidor de estáticos podrá atender muchas peticiones simultáneas y responde muy rápido, por lo que un balanceo de carga de estáticos, pronto llegaría a su límite de conexiones y el servicio se ralentizaría más que acelerarse (depende de las máquinas de que dispongamos). Además, normalmente si una web carga muchos estáticos, éstos se piden simultáneamente en el navegador (primero llega el HTML de nuestra web y se analizan todos los archivos necesarios a partir de ahí: js, imágenes, css, tipos de letra, etc), entonces se piden intentando acelerar al máximo esta carga. Los navegadores, antiguamente hacían hasta 2 conexiones con cada host (dominio, subdominio, ip), ahora suelen hacer hasta 8 conexiones. Por lo que si aumentamos el numero de hosts desde los que servimos, las conexiones a los mismos serían simultáneas, es decir, que si disponemos de dos servidores estáticos, podríamos establecer hasta 16 conexiones al mismo tiempo y a los usuarios les beneficiaría bastante.
El caso en el que un balanceador de carga de estáticos nos beneficiaría a nosotros sería para introducir replicación y tolerancia ante fallos. Es decir, si se cae un servidor de estáticos detrás del balanceador, automáticamente utilizaremos otro.
Algo de hincapié en la arquitectura de red
Seguramente estemos acostumbrados a que todos los servidores que contratemos dispongan de una IP pública a la que podemos acceder (por SSH por ejemplo) para entrar y configurarlos. Eso está muy bien, aunque cuando estén configurados, deberíamos poder desengancharlos de esta red pública y utilizarlos a través de red privada. Muchos proveedores permiten esto. De esta forma, nuestro servidor no será accesible desde Internet, dándonos seguridad frente a intrusos (si hay algo que no queremos que sea hackeado, no lo conectemos a Internet).
En el caso de servidores de base de datos, cachés o servicios que utilice la web para funcionar de forma interna, nunca debemos dejarlos a la vista en Internet. Es más, en el caso del balanceador de carga, éste sí que tendrá acceso directo a Internet, pero cada uno de los nodos conectados no. En principio no habrá forma de acceder individualmente a uno de ellos desde una IP pública, sólo a través del balanceador, pero, es más, estos servidores web contarán con dos interfaces de red, uno que estará conectado a la red del balanceador y otro conectado a una red local interna donde estará conectado el servidor de base de datos. Por lo que para que alguien logre entrar en nuestra base de datos debería aprovechar una vulnerabilidad de nuestro servidor web (y lidiar con el balanceador de carga, al que podríamos poner un firewall delante para quitar muchas peticiones indeseadas).
Es más, muchas veces, cuando configuremos estos sistemas, no siempre nos interesaría dar acceso a Internet a las máquinas interiores. Es decir, al servidor de caché, ¿de verdad le interesa tener conexión a Internet? Tal vez sólo sea necesario cuando estemos configurando o actualizando los servidores. Cuanto más oculto a Internet esté un equipo, menos posibilidades de acceso desde fuera habrá.
Replicación de todo esto
El número de usuarios a los que podemos servir de forma simultánea es limitado. Y puede que hayamos llegado al límite de nuestro balanceador de carga que, como vemos, es un sólo punto de entrada. Es decir, al balanceador de carga, aunque su tarea es sencilla, si entra mucha gente, se puede quedar sin recursos, sin capacidad para establecer conexiones internamente con el resto de servicios, por lo que necesitaremos replicar esta estructura: otro balanceador de carga, con más servidores webs colgando de éste, y otra red interna que le da servicios a los servidores web.
Si tenemos que replicar esta estructura de nuevo deberíamos plantearnos cambiar de zona geográfica o centro de datos. Es decir, hasta ahora la replicación nos ha servido para atender a más clientes, o a evitar que un fallo en un nodo nos tumbe el sistema (si se nos cae un servidor web detrás del balanceador de carga no pasa nada, o si tenemos un cluster de base de datos, con replicación haría lo mismo con este subsistema). Entonces, por un lado, si tenemos nuestra arquitectura en un centro de datos europeo, pero también nos llega gente en Estados Unidos, sería una buena idea a la hora de replicar la infraestructura, hacerlo en un centro de datos americano. Aunque si, por ejemplo tenemos un servicio territorial (todos nuestros clientes nos llegan de España), sería una buena idea replicarlo todo en un datacenter diferente porque siempre se puede caer el datacenter actual, o por ejemplo tener un problema de red, de forma que nuestro servicio permanezca siempre en pie.
Dos puntos importantes y no mencionados
Hay dos temas que se han quedado atrás, y no por ello son menos importantes: la monitorización y gestión de logs. Por un lado, debemos siempre conocer el estado de salud de nuestros servicios. En el caso en el que tengamos varios servidores web detrás de dos balanceadores, con algunos servidores de base de datos, cachés, almacenamiento, etc. Debemos saber en todo momento cómo están funcionando.
Si era importante conocer el estado de nuestro servidor cuando sólo era uno, aunque era sencillo pudiendo ejecutar algunos comandos, cuando tenemos tantas máquinas desplegadas necesitamos sistemas que nos automaticen un poco la obtención de información y si puede ser que esté todo centralizado.
Se pueden dar muchos casos, pero imaginemos que hay un nodo caído tras el balanceador de carga. Nuestra aplicación funciona perfectamente, no notamos nada, pero estaremos pagando por una máquina que no está funcionando, o tal vez no tengamos acceso a nuestra aplicación web y no sepamos por lo que es, y es que si la aplicación tira de tantos nodos, cualquiera de ellos puede ser el causante del fallo. Debemos tener un sistema que nos ayude a averiguar qué está fallando.
Junto con la motorización, viene la gestión de logs. Son muchas máquinas, y generan muchos informes, tanto de accesos, como errores, y recogerlos uno a uno es un trabajo de chinos. Necesitamos un sistema que centralice los logs y separe la paja de la información necesaria. Tal vez los servidores generan muchas notificaciones para tareas que han ido bien y no nos interesa conservarlas. Por otro lado, muchas veces se nos obliga a mantener logs de acceso a sistemas durante un tiempo con informes más o menos detallados.
Si tenemos una infraestructura tan grande, generaremos muchos logs y podemos utilizar muchos sistemas para gestionarlos y sobre todo acceder de forma centralizada a los mismos (esto nos ayudará mucho en el futuro). Por otro lado, a veces, hay máquinas que no serán persistentes, es decir, si tenemos un balanceo de carga con auto escalado, normalmente se crearán máquinas y se destruirán, por lo que los accesos a esas máquinas (el log), lo perderemos cuando se destruya, y eso no debe ser así. Nuestro sistema de recopilación de logs debe adaptarse.
Y tú, ¿qué arquitectura utilizas para tus aplicaciones web?
¿Estás pensando en renovar la arquitectura de tus aplicaciones? ¿Te has encontrado con algún problema? ¿Quieres compartir tus soluciones o tu visión?
¡Deja un comentario!
La próxima semana, haremos un ejemplo de configuración de balanceador de carga con Amazon Elastic Load Balancer.
Foto principal: Deniz Altindas






Pingback: Introducción a la escalabilidad de aplicaciones web. Técnicas, opciones, seguridad y consejos. | PlanetaLibre /
Pingback: Balanceo de carga con Amazon Web Services Elastic Load Balancer. Ejemplos, consejos y trucos. – Poesía Binaria /
Pingback: Cómo configurar auto escalado asociado al balanceador de carga de Amazon Web Services – Poesía Binaria /
Pingback: Lista de control para instalar un servidor para tu web, blog, correo y más (Checklist para servidor) – Poesía Binaria /
Pingback: Aplicaciones web sin servidor, o casi (arquitecturas serverless) – Poesía Binaria /
En el diagrama no separas los «Web Servers» de los «Applications Servers» lo que me hace intuir que crees que un Tomcat (por decir) puedes dejarlo expuesto a 1-Internet y 2-La cantidad de peticiones que le entren. Esto vale para webs de andar por casa pero si haces esto en un entorno corporativo vas a tener un problema bien gordo en cuanto a seguridad y fiabilidad de la plataforma cuando haya carga
Pues mira, llevas razón, en el diagrama podía separar estos servidores. Al menos cuando ya estemos haciendo algo grande. Es cierto que algunas veces están juntos (aunque no tengan puerto abierto al exterior, pero en configuraciones pequeñas se mira más por la economía, además de que no suelen estar muy cargados esos servidores).
Espero actualizar el post un día de estos, además, tengo algo más de material para añadir y actualizar.
Gracias por tu comentario.
The sheer size and selection of these web slots are mind-blowing. Great job. สล็อตเว็บใหญ่
I utilize just astounding materials – you can see them at: 91club app
Quality matters, and slots that break easily are a big letdown. สล็อตแตกง่าย
Good subject, comparative writings are I don’t know whether they are on a par with your work out. Spanish coach trips
I require you to thank for your period of this extraordinary read!!! I definately welcome every last bit of it and I have you bookmarked to take a gander at new stuff of your blog a certain prerequisite read blog! B2C booking platform
I require you to thank for your period of this radiant read!!! I definately value every last bit of it and I have you bookmarked to take a gander at new stuff of your blog an outright need read blog!!!! เว็บสล็อตทุกค่าย
This is also a fair post which I really savored the experience of scrutinizing. It isn’t every day that I have the probability to see something like this.. France bus tours
For this situation you will start it is essential, it again creates a site a solid noteworthy web webpage: เว็บสล็อตโรม่า
So it is intriguing and great composed and see what they think about other individuals. เกมป๊อกเด้งออนไลน์
The variety of slot machines in online casinos is mind-blowing. From classic fruit slots to modern, themed ones, there’s always a new game to try. 플러스카지노
I’m still processing it in my mind since I’m not familiar with other terms and I’m not that familiar with web application scalability so I need to study it well. But it is a great post and thanks for sharing it with us.
Local SEO Citations
Unlock the power of Custom AI Agents with Taskade – your tool to create personalized AI assistants. Tailor them to handle tasks like content creation, web research, coding, and more, optimizing your workflow with intelligent automation. Perfect for businesses seeking efficient, AI-driven solutions. AI Agents in Business Efficiency
This substance is just energizing and innovative. I have been settling on an institutional move and this has helped me with one angle. Animal Control Brampton
This is energizing, in any case it is imperative for you to visit this particular url: Blocked driveway towing
I positively enjoy each little bit of it and have you bookmarked to take a look at new stuff in your weblog post. love poetry in Urdu/a>
Locate the best articles on is my companion’s profile page. cash for junk cars
I am continually hunting on the web down articles that can help me. There is clearly a great deal to think about this. I think you made some great focuses in Features too. Continue working, extraordinary job ! รับจำนำรถจอด
So parcel to happen over your astounding site. Your blog acquires me a phenomenal exchange of charming.. Salubrious part alongside the scene. transmission rebuilt
Welcome to the gathering of my life here you will master every little thing about me. concierge doctor naples
Benefit basically prime quality things – you can comprehend them all inside: ฝากถอนไม่มีขั้นต่ำ
I would endorse my profile is crucial to me, I invite you to look at this subject… sod gold buy
It is incredibly average to see the best inconspicuous components presented in a basic and seeing way. Squirrel Removal Brampton
I Like!! Really appreciate you sharing this blog post.Really thank you! Keep writing.
Online Sabong Update
Nadama mo ba ang galing ng artikulong ito? Dalhin ang galing mo sa CasinoPlus Jili Game, at tuklasin ang higit pa! Color Game
I was curious if you ever considered changing the layout of your site? Its very well written; I love what youve got to say.
But maybe you could a little more in the way of content so people could connect with it better.
Youve got an awful lot of text for only having one or 2 images. Maybe you could space it out better?
Health
Understanding user numbers and resource needs is crucial before diving into scaling efforts.
ufa wallet 789 ผู้ให้บริการสปอร์ตออนไลน์ และคาสิโนเต็มรูปแบบ เล่นเพลินเกินห้ามใจ ทำกำไรได้ทุกวัน
ufa789 เข้าสู่ระบบ เว็บแทงบอลที่ใหญ่ และการเงินมั่นคงที่สุด สล็อตออนไลน์ ไม่มีขั้นต่ำ ใช้ทุนน้อย เล่นได้ทุกเกม
Thank you so much for your kind words and support! I’m truly honored to be a part of your learning journey and to assist you whenever you need guidance or have questions about new topics. Your enthusiasm for learning is inspiring, and I’m excited to continue exploring new subjects and expanding our knowledge together.While I can’t provide real-time trends, I can suggest some classic and popular wavy hairstyles for men that have stood the test of time:wavy hairstyles men/
Thank you so much for your kind words and support! I’m truly honored to be a part of your learning journey and to assist you whenever you need guidance or have questions about new topics. Your enthusiasm for learning is inspiring, and I’m excited to continue exploring new subjects and expanding our knowledge together.Armed Bodyguards New York