

Hace años, más o menos a finales del siglo XX y principios del XXI y, como vimos en mi anterior post, hubo una guerra por los Megahercios. Es decir, las grandes compañías de procesadores, en aquella época Intel y AMD que, aunque había más fabricantes, éstos eran los que más sonaban, peleaban para que sus procesadores corrieran más que los de la competencia. Es más, como el usuario de a pie siempre se ha regido por la frase: «burro grande, ande o no ande«, siempre querrá un procesador con más megahercios, una cámara con más megapixels o una televisión con más pulgadas.
Pero ahora vivimos una realidad un poco distinta. Los procesadores actuales, que podemos tener en nuestro ordenador personal o encontramos en un servidor, grosso modo, intentan hacer operaciones más complejas utilizando menos ciclos, realizar varias operaciones a la vez y, también, consumir menos energía. Es más, en 2004 se alcanzaron los 4GHz, y pocos procesadores actuales los superan. Para entendernos mejor, antes sabían sumar, restar, multiplicar y dividir. Y, cuando queríamos hacer una raíz cuadrada teníamos que hacerlo en función de las operaciones que sabíamos hacer. Pero ahora las CPUs saben hacer raíces cuadradas sin necesidad de más indicaciones. Al mismo tiempo, si tenemos que hacer muchas operaciones, podemos agruparlas y procesar varios grupos a la vez. Esta explicación no es muy exacta, pero así nos hacemos una idea de cómo va la cosa.
Hoy vamos a centrarnos en la capacidad de desempeñar varios trabajos a la vez por la CPU. Y eso vendrá determinado por el número de núcleos o de hilos de ejecución que sea capaz de ejecutar dicha CPU. Por supuesto, el buen funcionamiento del sistema vendrá determinado por cómo el sistema operativo reparta las tareas entre los núcleos del procesador. O si, por ejemplo, tenemos una placa base con varias CPU, cómo se repartan las tareas entre éstos.
Tabla de contenidos
Varios procesos diferentes
Empecemos por el principio. Una vez que los sistemas operativos han evolucionado, y ya son capaces de manejar los núcleos como churros, podemos ver cómo si ejecutamos varias aplicaciones pesadas en nuestro sistema, éstas se ejecutan utilizando varios núcleos. Mientras que si sólo ejecutamos una, sólo habrá un núcleo trabajando.
Como vemos en las siguientes imágenes, podemos ver cuándo había sólo una aplicación gorda (por así decirlo) corriendo. En este caso sólo está trabajando intensamente la CPU3, las demás, algo también, porque un ordenador ejecuta muchos servicios.

Pero como vemos en la siguiente imagen, hay dos CPUs trabajando intensamente, la CPU4 y la CPU5. Porque tengo dos programas de cálculo corriendo a la vez (el segundo terminó muy pronto, pero se puede ver el intervalo de trabajo).

Cuando un proceso necesita músculo
Pero seguro que se nos ocurren tareas en las que necesitamos mucha más potencia de cálculo. Éstas pueden ser, por citar algunos ejemplos: compresión/descompresión de vídeo, simulaciones, procesamiento 3D, tratamiento de imagen, criptografía, etc. Son procesos que, pueden llevar mucho tiempo y, aunque podremos lanzar varios procesos iguales a la vez y comprimir 4 vídeos en el tiempo que se tarda en comprimir uno solo. A nosotros nos interesaría poder comprimir uno, pero en una cuarta parte del tiempo…

Es cierto que la compresión de vídeo es un terreno que ya está muy dominado en este aspecto. Existe tanto software como hardware especializado en realizar esta tarea de manera muy eficiente y muy rápida (como hablaré en futuros posts, podemos, por ejemplo, utilizar ffmpeg o avconv para comprimir vídeo utilizando varios núcleos y acelerar dicho proceso). Pero siempre está bien poder hacer lo mismo por nosotros mismos a la hora de crear un programa que realice un cálculo complejo, o un efecto, o análisis de imagen. De la misma manera de antes, ya que tenemos varios núcleos en nuestro ordenador, nos interesa terminar pronto en lugar de hacer varias imágenes a la vez. Incluso en un programa de edición de vídeo, nos interesa tener una previsualización en tiempo real y, a veces, en la máxima resolución posible.
Algunas cosas a tener en cuenta
Eso sí, para aprovechar el multiprocesamiento, y hacer que varios núcleos puedan coordinarse para procesar el trabajo que queremos y sacarlo antes, primero necesitamos optimizar nuestros algoritmos para ello y tener en cuenta algunas cosas:
- Tenemos que independizar los cálculos lo más posible. Es decir, si un cálculo depende del resultado de la iteración anterior, no vamos a poder paralelizar el cálculo total. Aunque, por ejemplo, si queremos aplicar un filtro a una imagen (si no anula lo que he dicho en la frase anterior), sí que podemos dividirla en trozos y procesar cada trozo por separado. O, si es un sumatorio, y cada elemento se puede calcular de forma independiente, podemos calcular y sumar resultados parciales y, cuando acabemos, sumar los resultados parciales… ya lo iremos viendo.
- Cuidado con la memoria. Es aconsejable utilizar, en la medida de lo posible, zonas de memoria diferentes en cada uno de los hilos de ejecución que lancemos para evitar condiciones de carrera, o el tener que introducir mutex o bloqueos a la hora de acceder a un dato.
- ¡Cuidado con los bloqueos! Un poco realacionado con el punto anterior. Si necesitamos hacer que un hilo espere a otro, puede que tengamos potencia desaprovechada y tardemos mucho. Hay veces que es inevitable, pero en muchos casos no.
- Monitorizar el tiempo. Si una tarea, programada para un sólo hilo, imaginemos que tarda 10 segundos. Cuando la programamos de forma multihilo y lanzamos dos hilos, es muy difícil que tarde la mitad, 5 segundos. Tal vez, tardará 6 segundos, y si lanzamos 3 hilos, se aproximará a 5 segundos. Esto está bien, ya que seguramente tengamos algún acceso más a variables, tendremos que acceder a algún dato de otra forma, o incluso hacer operaciones antes y después del procesamiento en grupo. Eso sí, si procesando con dos hilos tardamos 9 segundos, o más de 10 pueden pasar dos cosas: o la tarea no es viable en multiproceso, o estamos haciendo algo mal.
- ¿Es viable el multiproceso? Hay tareas que tardan tan poco que no merece la pena ponerse a paralelizarlas. O, al menos, complicarnos la vida para ello. Es decir, muchas veces, para paralelizar una tarea, tenemos que preparar los datos datos, realizar el procesamiento y reorganizar los datos de nuevo. Así que el hecho de preparar los datos y reorganizarlos, no debe invertir mucho tiempo. Como ejemplos de esto, podemos pensar, en calcular un sumatorio, debemos reservar memoria para hacer sumas parciales y definir qué parte calculará cada hilo. Cuando termine el procesamiento debemos sumar todas las sumas parciales. Vemos que el proceso se complica un poco, así que, en operaciones muy sencillas y rápidas, tal vez la preparación y reorganización tarden mucho en comparación con el cálculo y estaremos perdiendo tiempo.
Hilos y núcleos
Para realizar el reparto de tareas, vamos a crear varios hilos de ejecución en nuestro programa. El sistema operativo se va a encargar de repartir estos hilos entre los núcleos o cores de nuestra CPU (o los hilos que sea capaz de ejecutar, porque muchas CPUs pueden correr dos hilos por cada core. A lo mejor no son dos hilos simultáneos simultáneos, pero casi). Aunque, por ejemplo si nuestro ordenador puede ejecutar 4 hilos a la vez, como poder, podemos lanzar 10 o 12 hilos. En este caso, esos 12 hilos se van repartiendo el tiempo en los 4 núcleos y, si la tarea a realizar es muy pesada, puede que el multiprocesamiento nos haga perder tiempo.
De toda la vida de la informática, o gran parte de ella, hemos tenido un núcleo y ese núcleo ha tenido que ejecutar cientos de tareas pequeñas. El núcleo se las ha repartido para que parezca que se ejecutan a la vez. Si tenemos 4 núcleos, los 4 se repartirán las tareas.
Repartir tareas entre hilos
Existen muchas técnicas para el multiprocesamiento. Por ejemplo, cuando tenemos un servidor (web, base de datos, ftp, etc), normalmente se crearán varios hilos dependiendo de las peticiones que vayan entrando. O puede que necesitemos varios hilos corriendo constantemente generando y recibiendo datos a la vez.
Aunque en este post me voy a centrar en bucles, tareas que podemos hacer de forma iterativa, de las que conocemos su inicio y su final. Y por eso los ejemplos sobre compresión y cálculos. Procesos del tipo: tengo que dar 100 iteraciones, del 0 al 99 y tengo 4 núcleos:
- núcleo0, tú darás darás las 25 primeras, del 0 al 24 (for i=0;i
- núcleo1, las siguientes 25, del 25, al 49 (for i=25;i
- núcleo2, las siguientes, del 50 al 74 (for i=50;i
- núcleo3, las restantes, del 75 al 99 (for i=75;i
Por lo que ahora, el inicio y el fin del bucle tendremos que calcularlo en función del número de hilos que vayamos a lanzar, no es difícil, ni pesado, pero ya estamos haciendo cosas que antes no hacíamos.
Si, por ejemplo tenemos un bucle for que se inicia en 0 y finaliza en n, cada hilo tendrá su propio bucle for desde:
![]()
y terminará en:
![]()
Por supuesto, dadas estas fórmulas, cada hilo sabe qué número de hilo es y cuántos vecinos tiene en ese procesamiento. Y así, sustituyendo, n=100, totalHilos=4 e hilo, dependiendo del hilo actual por 0,1,2,3 nos saldrán los números de antes. Ya de manera general, si tenemos un inicio que no es 0, llamémosle xi y un fin xf, podemos decir, de manera general que:
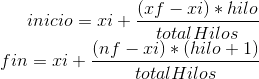
Donde siempre podemos coger, sacar (xf-xi), llamarlo n y nos queda algo muy parecido a lo de antes.
Uso de bibliotecas
¡Cómo no! Hay herramientas que permiten hacer esto en muchos lenguajes, por ejemplo, ya que estamos con C++, tenemos OpenMP capaz de hacer muchas cosas. Pero hoy vamos a centrarnos un poco en teoría, matemáticas y cómo funciona todo esto.
¡Ejemplos, ejemplos!
Cálculo de PI
Para los ejemplos voy a utilizar C++11, más que nada porque no tenemos que liar mucho jaleo para hacer threads. Empecemos calculando el número Pi con la fórmula:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | #include <chrono> #include <iostream> #include <thread> #include <list> #include <iomanip> using namespace std; int Nthreads; double* sump; //Array donde se guardarán las sumas parciales void calcula_pi (int hilo, long unsigned n, double h) { double sp=0.0; // La suma parcial la hacemos en un espacio de memoria cercano, que será más rápido for (long unsigned i=(n*hilo/Nthreads); i <(n*(hilo+1))/Nthreads; i++) { // Cálculamos Sum[i=0, i=n] 4 / (1 + (1/n * (i-0.5)^2) siendo h=1/n mediante sumas parciales en // cada hilo double x = h * ((double)i - 0.5); sp+= 4.0 / (1.0 + x*x); } // Por último rellenamos el espacio correspondiente del array de // sumas parciales. sump[hilo]+=sp; } int main(int argc, char *argv[]) { double mypi, sum=0; double h ; long unsigned n; // Parseamos argumentos. El primer argumento será n y el segundo el número de hilos // Por defecto, n=100 y el número de hilos=1 n= 100; Nthreads = 1; if (argc > 2) { n = atoi(argv[2]); Nthreads = atoi(argv[1]); } else if (argc > 1) { Nthreads = atoi(argv[1]); } auto time_inicio=chrono::high_resolution_clock::now(); // Preparación del entorno: reserva de memoria. sump=new double [Nthreads]; list<thread> threads; // Procesamiento del dato // Evitamos que todos los threads calculen un dato común. // h = 1/n, además, lo sacamos del sumatorio. h = 1.0 / (double) n; // Cálculo de PI con 1/n * Sum[i=0, i=n] 4 / (1 + (1/n * (i-0.5)^2) for (int i=0; i<Nthreads; i++) { // Lanzamos threads que ejecutan la función calcula_pi, les pasamos su número // de thread, n y h threads.push_back(thread(calcula_pi,i,n, h)); } // Cada thread lo unimos al proceso principal, por lo que esperamos que terminen // todos los threads lanzados. for (auto &t: threads) { t.join(); } // Fin del procesamiento y ahora iniciamos la reorganización, en este caso // sumamos las sumas parciales en una sola variable y liberamos memoria for (int i=0;i<Nthreads;i++) { sum=sum+sump[i]; } mypi = h * sum; delete [] sump; auto time_fin=chrono::high_resolution_clock::now(); cout << "Tiempo invertido: " << chrono::duration<double,milli>(time_fin-time_inicio).count() << " ms, con: "<<Nthreads<< " hilos." << endl; cout << "PI= "<<setprecision(9)<<mypi<<endl; return 0; } |
Este ejemplo tal vez tendría más sentido si utilizáramos precisión arbitraria, aunque como ejercicio no viene mal.
Para compilar este ejemplo debemos hacer:
Modificando una imagen jpeg
Para terminar, vamos a modificar el brillo y contraste de una imagen de una imagen por componentes. Pudiendo aumentar brillo y contraste de rojos, verdes o azules por separado. Utilizaré el ejemplo del post del enlace, aunque añadiré algunas modificaciones para hacerlo multihilo.
He de decir que no he optimizado mucho el código, por lo que, seguro que trabajando un poco más en él se pueden conseguir mejores resultados. Además, hay que tener en cuenta que la lectura y escritura del fichero de imagen no es multiproceso por lo que esto es un tiempo fijo que nuestro programa tiene que invertir.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 | #include <stdio.h> #include <jpeglib.h> #include <stdlib.h> #include <math.h> #include <chrono> #include <iostream> #include <thread> #include <list> using namespace std; typedef struct TImage { int width; int height; int bytes_per_pixel; int color_space; int size; unsigned char *data; } TImage; int read_jpeg_file( char *filename, TImage *img ) { /* these are standard libjpeg structures for reading(decompression) */ struct jpeg_decompress_struct cinfo; struct jpeg_error_mgr jerr; /* libjpeg data structure for storing one row, that is, scanline of an image */ JSAMPROW row_pointer[1]; FILE *infile = fopen( filename, "rb" ); unsigned long location = 0; int i = 0; if ( !infile ) { printf("Error opening jpeg file %s\n!", filename ); return -1; } /* here we set up the standard libjpeg error handler */ cinfo.err = jpeg_std_error( &jerr ); /* setup decompression process and source, then read JPEG header */ jpeg_create_decompress( &cinfo ); /* this makes the library read from infile */ jpeg_stdio_src( &cinfo, infile ); /* reading the image header which contains image information */ jpeg_read_header( &cinfo, TRUE ); /* Uncomment the following to output image information, if needed. */ img->width=cinfo.image_width; img->height=cinfo.image_height; img->bytes_per_pixel=cinfo.num_components; img->color_space=cinfo.jpeg_color_space; /* Start decompression jpeg here */ jpeg_start_decompress( &cinfo ); /* allocate memory to hold the uncompressed image */ img->size=cinfo.output_width*cinfo.output_height*cinfo.num_components; img->data = (unsigned char*)malloc( img->size ); /* now actually read the jpeg into the raw buffer */ row_pointer[0] = (unsigned char *)malloc( cinfo.output_width*cinfo.num_components ); /* read one scan line at a time */ while( cinfo.output_scanline < cinfo.image_height ) { jpeg_read_scanlines( &cinfo, row_pointer, 1 ); for( i=0; i<cinfo.image_width*cinfo.num_components;i++) { img->data[location++] = row_pointer[0][i]; } } /* wrap up decompression, destroy objects, free pointers and close open files */ jpeg_finish_decompress( &cinfo ); jpeg_destroy_decompress( &cinfo ); free( row_pointer[0] ); fclose( infile ); /* yup, we succeeded! */ return 1; } /** * write_jpeg_file Writes the raw image data stored in the raw_image buffer * to a jpeg image with default compression and smoothing options in the file * specified by *filename. * * \returns positive integer if successful, -1 otherwise * \param *filename char string specifying the file name to save to * */ int write_jpeg_file( const char *filename, TImage *img ) { struct jpeg_compress_struct cinfo; struct jpeg_error_mgr jerr; /* this is a pointer to one row of image data */ JSAMPROW row_pointer[1]; FILE *outfile = fopen( filename, "wb" ); if ( !outfile ) { printf("Error opening output jpeg file %s\n!", filename ); return -1; } cinfo.err = jpeg_std_error( &jerr ); jpeg_create_compress(&cinfo); jpeg_stdio_dest(&cinfo, outfile); /* Setting the parameters of the output file here */ cinfo.image_width = img->width; cinfo.image_height = img->height; cinfo.input_components = img->bytes_per_pixel; cinfo.in_color_space = JCS_RGB; //img->color_space; /* default compression parameters, we shouldn't be worried about these */ jpeg_set_defaults( &cinfo ); /* Now do the compression .. */ jpeg_start_compress( &cinfo, TRUE ); /* like reading a file, this time write one row at a time */ while( cinfo.next_scanline < cinfo.image_height ) { row_pointer[0] = &img->data[ cinfo.next_scanline * cinfo.image_width * cinfo.input_components]; jpeg_write_scanlines( &cinfo, row_pointer, 1 ); } /* similar to read file, clean up after we're done compressing */ jpeg_finish_compress( &cinfo ); jpeg_destroy_compress( &cinfo ); fclose( outfile ); /* success code is 1! */ return 1; } float _byc(int hilo, int Nthreads, TImage *img, double bred, double bgreen, double bblue, double cred, double cgreen, double cblue) { int i; double tanred, tangreen, tanblue; unsigned char vred, vgreen, vblue; int v; tanred=tan ((cred + 1.0) * 0.78539816); tangreen=tan ((cgreen + 1.0) * 0.78539816); tanblue=tan ((cblue + 1.0) * 0.78539816); for (i=img->size*hilo/Nthreads; i<img->size*(hilo+1)/Nthreads; i+=3) { vred = img->data[i]; vgreen = img->data[i+1]; vblue = img->data[i+2]; if (bred<0) vred=round(vred*(1+bred)); else vred+=round((255-vred)*bred); if (bgreen<0) vgreen=round(vgreen*(1+bgreen)); else vgreen+=round((255-vgreen)*bgreen); if (bblue<0) vblue=round(vblue*(1+bblue)); else vblue+=round((255-vblue)*bblue); v=round( (vred - 128) * tanred) + 128; if (v>0 && v<255) vred=v; else if (v<0) vred=0; else vred=255; v=round( (vgreen - 128) * tangreen) + 128; if (v>0 && v<255) vgreen=v; else if (v<0) vgreen=0; else vgreen=255; v=round( (vblue - 128) * tanblue) + 128; if (v>0 && v<255) vblue=v; else if (v<0) vblue=0; else vblue=255; img->data[i] = vred; img->data[i+1] = vgreen; img->data[i+2] = vblue; } } float byc(int Nthreads, TImage *img, double bred, double bgreen, double bblue, double cred, double cgreen, double cblue) { list<thread> threads; for (int i=0; i<Nthreads; i++) { threads.push_back(thread(_byc,i,Nthreads, img, bred, bgreen, bblue, cred, cgreen, cblue)); } for (auto &t: threads) { t.join(); } } int main(int argc, char*argv[]) { char infilename[] = "street-601320.jpg"; TImage img; int Nthreads =1; if (argc >= 2) { Nthreads = atoi(argv[1]); } /* Try opening a jpeg*/ if( read_jpeg_file( infilename, &img ) > 0 ) { auto time_inicio=chrono::high_resolution_clock::now(); byc(Nthreads,&img, 0.1, 0.1, 0.2,0.1, -0.1, 0.8); auto time_fin=chrono::high_resolution_clock::now(); cout << "Tiempo invertido: " << chrono::duration<double,milli>(time_fin-time_inicio).count() << " ms, con: "<<Nthreads<< " hilos." << endl; write_jpeg_file("foto_brillo.jpg", &img); } return 0; } |
Para compilar debemos hacer:






Pingback: Cómo distribuir cálculos entre varios núcleos para acelerar procesos de computación [ejemplos en C++] | PlanetaLibre /
Great site you have here wordle answer today. It’s hard to find high-quality writing like yours nowadays. I honestly appreciate individuals like you!
This is a great inspiring article. I am pretty much pleased with your good work.You put really very helpful information.Yellowstone Official Merchandise
Very nice
Esto también funciona para acelerar los cálculos en las computadoras de su automóvil. Al menos eso es lo que aprendí en mi taller local de carrocería.
I think this method has been so effective since it worked for me and to some of my friends.
goplus electric bike
It proved to be an incredible article. This is an important topic. This website offers several benefits. It has lots of important information. It benefits me in a variety of ways. Thank you for bringing this to our attention. Leather Outwears
These tips really help. Thanks!
There’s no doubt i would fully rate it after i read what is the idea about this article. You did a nice job.
golf betting tips
I’m glad I’ve found your website. You provide a lot of useful information! arvada concrete patio
I found this post very interesting and informative. Thank you for sharing your special thoughts with us. My site: rugby vs american football
Our agency provides Gurgaon Call Girls WhatsApp Number, available with just a single click. You can contact our staff members; they will assist you in fulfilling your needs and arrange a meeting with our beautiful escorts.