{kind=link}
Algo que nos puede traer de cabeza como administradores de sistemas y, a veces como usuarios es el hecho de que un proceso se coma, devore y trate sin piedad la CPU de nuestro sistema. Ya no solo el hecho de que un programa deje inservible el ordenador, aunque a día de hoy con tantos núcleos de procesador, casi siempre tendremos algo de CPU para enviar una señal de parada a un proceso. Un ejemplo más claro puede que tengamos dos programas en ejecución (o más), uno de ellos nos corre más prisa que el otro, ¡pero el ordenador no lo sabe! Así que, si utilizan la CPU de forma intensiva terminarán utilizando el 50% de la CPU cada uno.
Pero claro, un proceso necesitamos que esté listo antes, lo lógico es asignarle más CPU a éste. ¿Qué opciones tenemos?
Tabla de contenidos
La medida obvia, ejecución secuencial
Lo primero que se nos pasa por la cabeza es ejecutar primero el proceso que nos corre prisa, y cuando termine ejecutar el otro. Esto puede ser una buena solución en muchas ocasiones. Pero claro, ¿y si los procesos llevan lanzados ya un tiempo y han avanzado en su progreso? detener uno de ellos puede suponer la pérdida del estado que se ha conseguido. Puede que nos compense, o puede que no.
¿Y si estamos hablando de programas demonio? Los programas están en ejecución en segundo plano, haya momentos de gran utilización de CPU y momentos en los que no se usa, pero sí sabemos que uno tiene preferencia sobre otro. O al menos no queremos dejar sin CPU a los demás programas en ejecución.
Señales (peleando con la terminal)
Lo siguiente que se nos puede ocurrir es pausar y reanudar procesos. Si tenemos los procesos en dos terminales por separado, podemos pulsar Control+Z en el que deseemos pausar y luego escribir fg para reanudarlo. No tiene pérdida. Pero si los procesos no tienen un terminal, también podemos hacerlo enviándoles las señales SIGSTOP y SIGCONT. Para poner un ejemplo, he creado un pequeño script en Bash (muy tonto y lo he llamado consumidor.sh):
1 2 3 | #!/bin/bash while (( 1 )); do echo CONSUMO CPU; done |
Ahora lo ejecuto y me olvido de esa terminal porque no puedo tocarla. Desde otra terminal ejecuto top.
En lugar de consumidor.sh podríamos utilizar la siguiente línea:
Que se pondrá a calcular con un solo núcleo 100000 dígitos del número Pi.
Como vemos, tenemos un proceso consumidor.sh que está tirando bastante de CPU, así que, conociendo el PID (process ID o identificador de proceso) podemos ejecutar:
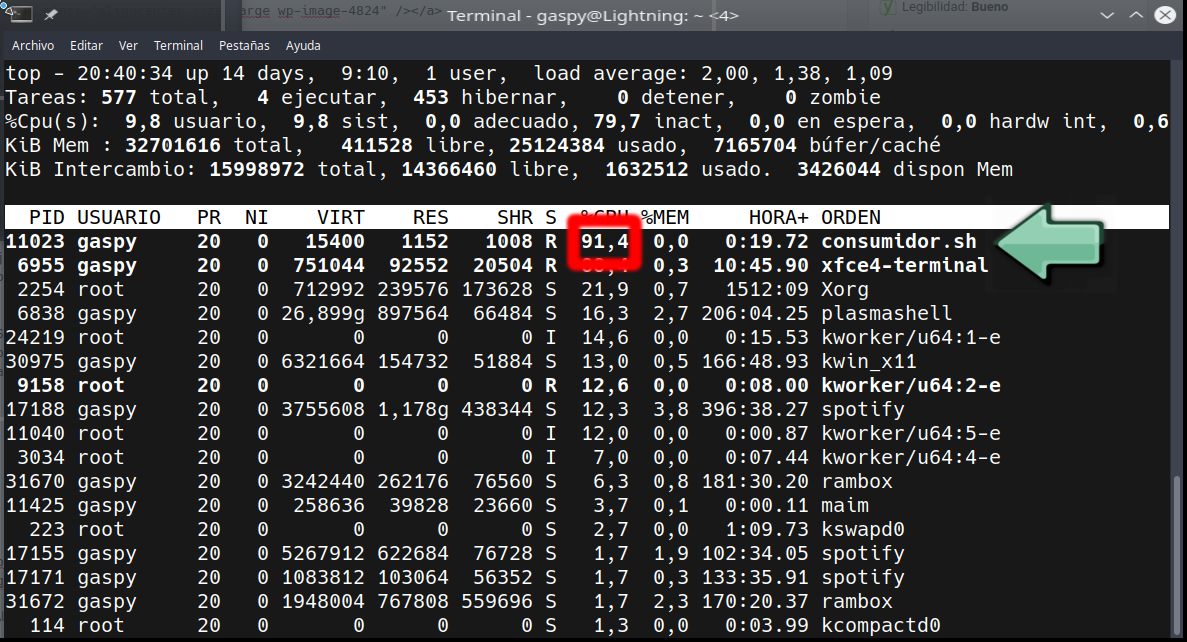{kind=link}
En ese momento vemos que ya no es un proceso que consuma CPU. Sigue en ejecución, pero está en pausa. Que no os asuste el comando kill, que no estamos matando a nadie, aún, sólo le decimos al sistema operativo que no le de más CPU hasta nueva orden, dicha orden es:
Y tras ejecutar esto volveremos a ver el proceso en cuestión dar guerra.
Si no queremos utilizar el PID del proceso, podemos hacerlo por su nombre utilizando (con cuidado, si tenemos varios procesos con el mismo nombre pararemos todos):
O el comando pkill de la misma manera.
De todas formas, es un engorro para nosotros estar todo el rato enviando señales es demasiado trabajo. Como humanos, si tenemos muchos procesos nos podemos confundir de PID y por otro lado tenemos que estar pendientes de cuando un proceso empieza a consumir CPU para pararlo. Si lo pensamos es una tarea muy automatizable.
Nice
La llamada del sistema que nos permite establecer la prioridad de un proceso con respecto al programador de tareas es nice. Pero solo es un pequeño factor que influye en la asignación de CPU a cada proceso por parte del sistema operativo. Imaginémonos una cola de supermercado, darle más nice a un proceso sería colocarlo un poco antes o después en la cola. El problema es que esta cola se repite muchas veces porque hay muchos procesos en ejecución (si tuviéramos que esperar que se terminara un proceso para ejecutar otro, nos podríamos olvidar de la multitarea y de muchas otras cosas). Si cada vez que un proceso se coloca en la cola, no lo ponemos el último, sino que lo colocamos más cerca de la caja, al final le estaremos asignando más tiempo de CPU al proceso.
Para ver resultados al cambiar el nice del proceso. Debemos tener una CPU pequeña (de un VPS pequeño, por ejemplo), o tener muchísimas tareas en ejecución, porque si tenemos CPU de sobra, el sistema siempre va a encontrar tiempo de CPU para un proceso. Si tenemos 8 core y estamos utilizando solo 2 al 100%, ahora queremos ejecutar otra aplicación (monohilo) con baja prioridad, el sistema verá que tenemos 6 core muertos de risa, así que la aplicación se ejecutará consumiendo el 100% de uno de los core sobrantes, porque ninguna otra aplicación reclama CPU, y el sistema ve que hay recursos de sobre. Por eso notaremos estos cambios cuando tengamos menos CPU para asignar.
Podemos ejecutar un programa con un nice determinado así:
Donde xx es un número entre -20 (más favorable) y 19 (menos favorable). Es decir, con -20 colaremos todo lo que podamos al proceso y con 19 lo pondremos lo más lejos de la caja que podamos. Con el 19, el proceso solo obtendrá tiempo de CPU cuando ningún otro proceso reclame CPU. Nota: También podemos usar nice -10 o nice 5, quitando el -n del medio, para teclear menos.
Pero también es posible cambiar el nice, o prioridad del proceso cuando éste está en ejecución, utilizando su PID (también podemos asignar prioridad a todos los procesos de un grupo o usuario con -u y -g):
En este caso también podremos quitar el -n si queremos.
ionice
Cuando un proceso utiliza además de CPU, entrada/salida de datos. Por ejemplo lectura y escritura de disco. Podemos acelerar o decelerar dicha operación. Normalmente un proceso cuando realiza una operación de disco, la solicita al sistema operativo. El proceso pasa a un estado de espera, porque no puede continuar sin el dato o el resultado de la operación, y cuando se hace efectiva, el sistema operativo vuelve a meter al proceso en la cola del programador de tareas para que pueda tener CPU de nuevo.
Ahora bien, si las operaciones de entrada/salida tardan poco, el proceso que las origina tardará menos en terminar. Las operaciones de I/O también van en cola y podemos hacer que éstas se realicen con prioridad máxima (tal cual entran, se realizan), con prioridad mínima (solo se llevarán a cabo cuando no haya ninguna otra operación de I/O por hacer), o en varios términos medios.
Si, por ejemplo, nuestro proceso solo usa CPU y poco I/O, cambiar esto apenas influirá.
Para cambiar el nice de IO (ionice), tenemos la orden ionice que podemos usar así:
Para establecer prioridad mínima, el argumento -c (clase) a 3 (idle, cuando el sistema está desocupado). O para máxima prioridad,
Siendo -c1 (clase 1, realtime o tiempo real) y -n0 (máxima prioridad dentro de la clase).
Como caso general -n obtendrá un valor entre 0 y 7 donde 0 es máxima prioridad y 7 es la mínima. Faltaría la clase 2 (best effort), que sería algo intermedio y también tendrá prioridades entre 0 y 7.
cpulimit/cputool
Ambos programas utilizan la misma técnica, y lo que hacen es automatizar el envío de señales SIGSTOP y SIGCONT a los procesos. Es decir, parar y reanudar procesos continuamente. De este modo es como si constantemente un programa estuviera mirando el porcentaje de CPU de top y si ve que un proceso se pasa de lo que hemos establecido, lo pausa, cuando ve que el porcentaje ha bajado, lo reanuda y así continuamente.
Como concepto está bien, pero claro, el propio cpulimit (cputool también) consume ya CPU, haciendo llamadas a sistema para ver el % de CPU de los procesos y luego hace más llamadas a sistema para pausar y reanudar procesos, por lo tanto estamos consumiendo CPU para ello. Es verdad que la cantidad de CPU que consumimos comparada con un proceso que devora CPU es pequeña, pero si en realidad el proceso devora CPU, la aplicación se pasa el rato pausando y reanudando.
Para probar esto, primero instalamos la utilidad cpulimit (seguro que nuestra distribución la tiene en su repositorio) y hacer lo siguiente:
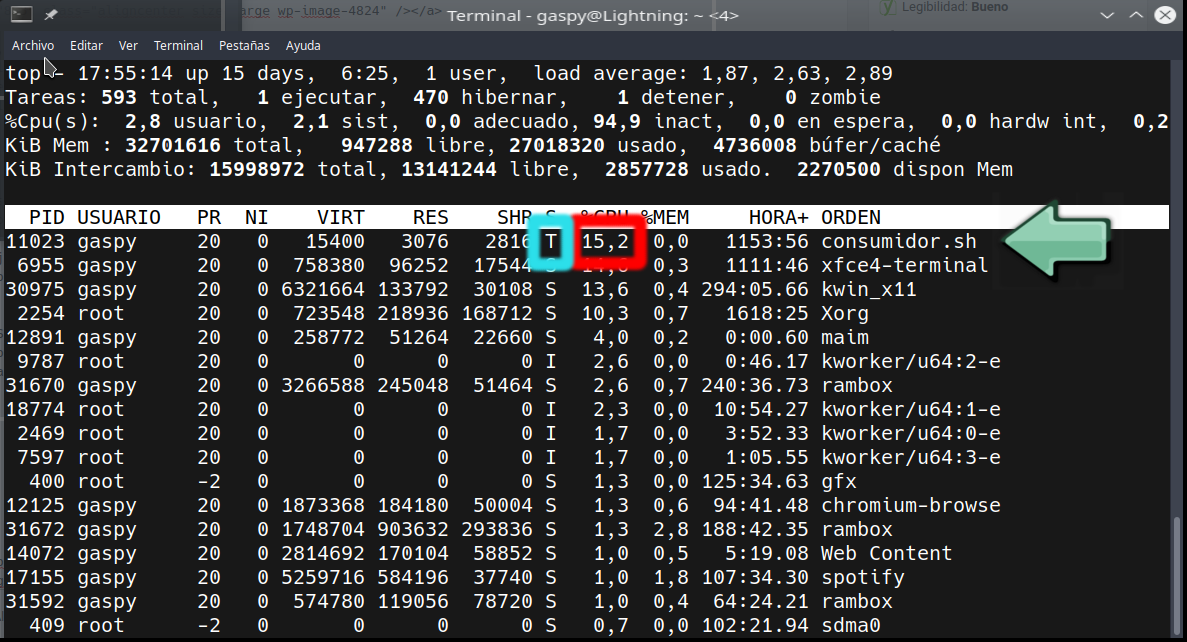
Con esto le decimos al proceso con PID 11023 (el que lanzamos antes) que no consuma más de un 10% de CPU. Esto no tendrá precisión científica, como vemos en la captura de pantalla (está consumiendo 15,2%) depende de muchos factores. El primero de ellos es el algoritmo con el que se calcula el porcentaje de CPU, que puede hacer que varíe un poco. También influye que el proceso cpulimit esté corriendo con un nice alto (al estar antes en la cola de la CPU hace más frecuentemente los cálculos de porcentaje de CPU y puede actuar antes) y que el proceso utilice gran cantidad de CPU, haga o no llamadas a sistema y demás acciones que pueden hacer que el programador de tareas se detenga más o menos en el proceso en cuestión.
Para observar el comportamiento de cpulimit, debemos observar la columna S del comando top (en la captura), veremos cómo el estado del proceso va cambiando de T (stopped, parado, cuando envían SIGSTOP) a R (running, en ejecución, cuando reanudan el proceso con SIGCONT).
{kind=link}
Cpulimit nos permite hacer algunas cosas más, como por ejemplo, con -m podemos monitorizar también todos los procesos hijos, porque muchos procesos se dividen en varios subprocesos nada más ejecutarse para trabajar.
Cputool funciona de forma parecida, en este caso, debemos utilizar -c:
Pero la técnica utilizada es la misma. Con el argumento -vv podremos ver cuándo cputool dice de pausar y cuándo de reanudar, es hipnótico y muy educativo, pero al final lo que hacemos es pausar y reanudar el proceso constantemente. Algo que pasa desde una aplicación, al kernel, o núcleo del sistema operativo, muchas veces.
Tanto con cputool como con cpulimit podemos ejecutar la aplicación directamente desde el comando y no especificar PID. En este caso serviría para aplicaciones que estamos ejecutando ahora y no para las que se encuentran ya en ejecución
Control Groups (cgroups)
Los grupos de control o control groups nos permiten limitar los recursos de un grupo de procesos en Linux. Estos grupos nos permiten controlar el tiempo de CPU, memoria, ancho de banda de red o de entrada/salida, etc. disponibles para ese grupo de procesos. Y en este caso es el kernel el que controla (como el nice), así que todo queda en casa, sin un proceso extra que regule y calcule y le diga al kernel lo que tiene que hacer (SIGSTOP, SIGCONT, etc). Configurar los control groups puede ser un poco más trabajoso que utilizar cpulimit, pero a la larga nos dará más alegrías. Además hablamos de grupos de procesos y no de procesos sueltos, por lo que podemos meter varios procesos en un grupo y tendrán las mismas políticas.
Los cgroups se usan muchísimo por docker, systemd, Hadoop, Kubernetes, LxC y muchos más proyectos. Son una herramienta potentísima para llevar el control de procesos.
Aunque sea el kernel el que controla y decide, necesitamos aplicaciones de espacio de usuario que definan los parámetros de control. Vamos, programas que hablen con el kernel para decir qué queremos; igual que kill, nice y demás utilidades.
Para ello podemos instalar las cgroup-toolso libcgroup-tools, dependiendo de la distribución puede tener otro nombre parecido. Una vez instaladas, nos disponemos a crear nuestro cgroup:
Con esto creamos un grupo dedicado a limitar CPU llamado cpulimitada. Podemos crear otro tipo de grupos que controlen memory: (memoria), cpuset: (que una aplicación use determinados núcleos), blkio: (entrada/salida), net-prio: (prioridad de red) y algunos más. Aunque este post se centrará en CPU.
Tras esto, debemos añadir nuestro proceso al cgroup (podríamos configurar el cgroup primero, pero como tenemos un terminal abierto con top, me gusta observar lo que pasa en todo momento. Para añadir nuestro proceso tenemos dos opciones, lanzar el proceso así:
Aunque, si por el contrario, el proceso ya está lanzado con anterioridad y queremos modificar su comportamiento podremos hacer lo siguiente:
Aunque se llamen grupos, un grupo de procesos puede contener un solo proceso, para hacer un ejemplo nos viene bien, luego podemos meter más procesos si queremos.
Una vez tenemos el proceso dentro de nuestro grupo y top no ha mostrado nada diferente ni raro. Por defecto, el grupo no tiene restricciones de CPU, podemos hacer lo siguiente:
La forma de dar el dato de cantidad de CPU a asignar es un poco diferente. Aquí establecemos los microsegundos de CPU que se dedicarán al proceso por intervalo de tiempo. En este caso dedicaremos 20000µs (20ms) por cada 0.1segundos (por cada 100000µs o 100ms), resultará un 20% del tiempo total. (20% de CPU)
Con cgroups estamos eliminando factores de la ecuación, por lo que no dependerá de un proceso externo, ni de la prioridad del proceso, además, no estaremos enviando señales y cambiando el estado del proceso constantemente. Será el propio kernel el que asigne CPU a un proceso o no. Por lo que todo será más limpio eficiente.
Con los cgroups podremos además definir de cuánto será el intervalo de tiempo (antes dijimos que era de 100000µs, que es el valor por defecto) de la siguiente forma y dejarlo en un segundo (1000000µs):
Tenemos mucho más control sobre los procesos con cgroups. Para obtener más información podemos echar un vistazo a la documentación de RedHat. Incluso podríamos controlar los cgroups desde el sistema de archivos (en muchas distribuciones tenemos los cgroups montados en /sys/fs/cgroup/, o podemos montar el directorio virtual donde queramos, igual que /proc).
Este post pretende ser solo una pincelada, así que para curiosear con las cgroup-tools podremos investigar los comandos: lscgroup, cgget, cgset, cgcreate, cgdelete. Hay más, pero creo que estos son los más importantes.
systemd-slices
Como dijimos antes, systemd utiliza muchísimo los cgroups, generalmente tiene un cgroup para cada servicio con todos los procesos que despliegue cada uno de ellos. Podemos personalizar todo esto. Ahora, creemos un servicio de systemd, que contenga lo siguiente (yo lo he llamado /etc/systemd/system/poesiatest.service):
{kind=link}
1 2 3 4 5 6 7 8 9 10 11 12 | [Unit] Description=Gascripts After=network.target [Service] Type=exec ExecStart=/home/gaspy/consumidor.sh CPUAccounting=true CPUQuota=20% [Install] WantedBy=multi-user.target |
Como hemos puesto al final de la etiqueta Service, utilizamos la clave CPUAccounting para indicarle a systemd que queremos limitar la CPU de ese servicio, y CPUQuota para especificar el porcentaje de CPU con el que lo vamos a limitar. Arrancamos el servicio:
Y cuando miremos top veremos que la CPU que consume dicho proceso está limitada al 20% (más o menos, siempre hay un poco de margen).
La gracia está en que podemos hacer que un servicio en ejecución varíe su cuota de CPU:
Pero esto no está limitado a servicios de systemd, podemos ejecutar un programa tal y como lo hacíamos con cpulimit, pero utilizando un slice que limite las características de la ejecución del programa. Por detrás utilizará cgroups, pero el resultado es mucho más amigable para el usuario (o sea, nosotros). Primero creamos la slice (luego podemos modificar sus características con systemctl set-property por lo que no es algo fijo). Nuestra slice será un archivo en /etc/systemd/system/mislice.slice que contiene:
1 2 3 4 5 | [Unit] Description=Mi slice [Slice] CPUQuota=40% |
Ahora para ejecutar un programa con esa slice hacemos:
Utilizaremos –user para ejecutar el programa como usuario.
Si por el contrario el proceso ya está iniciado, podremos utilizar cgclassify (como antes), ya que nuestro slice al final es un cgroup:
Y, por supuesto, sin ningún problema, podremos variar la cuota de CPU para dicho grupo:
Una forma justa de asignar CPU a grupos de procesos o cgroups es a través de shares. Son como participaciones en la rifa de tiempo de CPU. Como no estamos definiendo el porcentaje de CPU que le corresponde a cada grupo o a cada proceso es algo más difícil de ver. En este caso le estamos diciendo al sistema operativo la cantidad de CPU relativa que le corresponde a cada grupo.
Por ejemplo, tenemos 100 participaciones o shares y tenemos dos procesos. Un proceso tiene 50 y el otro tiene otras 50. Este es el caso por defecto, en el que el mismo tiempo de CPU le corresponde a cada proceso. Ahora bien, si un proceso tiene 75 y el otro 25. El proceso que más participaciones tiene tendrá más tiempo de CPU asignado que el proceso que tiene 25. Hasta aquí todo es más o menos lógico. La gracia de las participaciones está en la CPU que necesitan los procesos. Si por ejemplo el proceso que tiene 75 shares está esperando que el usuario pulse una tecla, y el proceso de 25 shares está calculando dígitos del número Pi (una tarea que utiliza intensamente la CPU), nuestro sistema operativo, mientras el usuario pulsa o no la tecla que requiere el primer proceso asignará el 100% de CPU (o toda la que sea posible) al proceso que solo tiene 25 participaciones. Es decir, las participaciones tienen efecto cuando hay una disputa por la CPU. En caso que haya CPU para todos los procesos, el sistema operativo entregará los recursos sin mirar mucho.
Por ejemplo, si tenemos un servidor web, y en la misma máquina un gestor de tareas en segundo plano para extraer información, procesar ficheros pesados de usuarios, etc. Nos interesa más que haya CPU para procesar las peticiones de los usuarios con la menor demora posible, por lo que si entra una nueva tarea de un usuario, no queremos que se lleve todos los recursos del procesador. Podemos hacer que el servidor web tenga 90 participaciones y el gestor de tareas tenga 10. Eso sí, si estamos en una hora en la que no tenemos usuarios en la web o tenemos muy pocos, el gestor de tareas podrá consumir toda la CPU si lo necesita.
Para utilizar las CPU shares, podemos hacerlo tanto con cgset como con systemctl set-property, de la siguiente manera:
Teniendo en cuenta que el número de shares que tiene un grupo por defecto es de 1024. En el ejemplo, estamos reduciendo la cantidad de participaciones, por lo que le bajamos prioridad a la asignación de CPU. Si queremos podemos subirla a 2048, 4096, etc. Personalmente, suelo utilizar múltiplos y submúltiplos de 1024 para hacer rápidamente el cálculo de probabilidad de cabeza. Pero podemos utilizar otras cantidades como 100, 1000, 1234, etc.
Es una buena técnica, sobre todo si estamos experimentando, anotar el valor de shares, que tiene un grupo (si no es de 1024), para eso podemos hacer:
Un detalle más sobre systemd y cgroups
Como hemos visto systemd también administra cgroups en nuestro sistema y, por defecto, crea muchos grupos y nos deja una configuración base hecha. Es cierto que solo están los procesos agrupados, pero no tenemos ninguna restricción, eso nos lo deja a nosotros. Pero si somos usuarios de una distribución que utilice systemd podemos sacar provecho de todo esto.
Solo tenemos que echar un vistazo a lo siguiente:
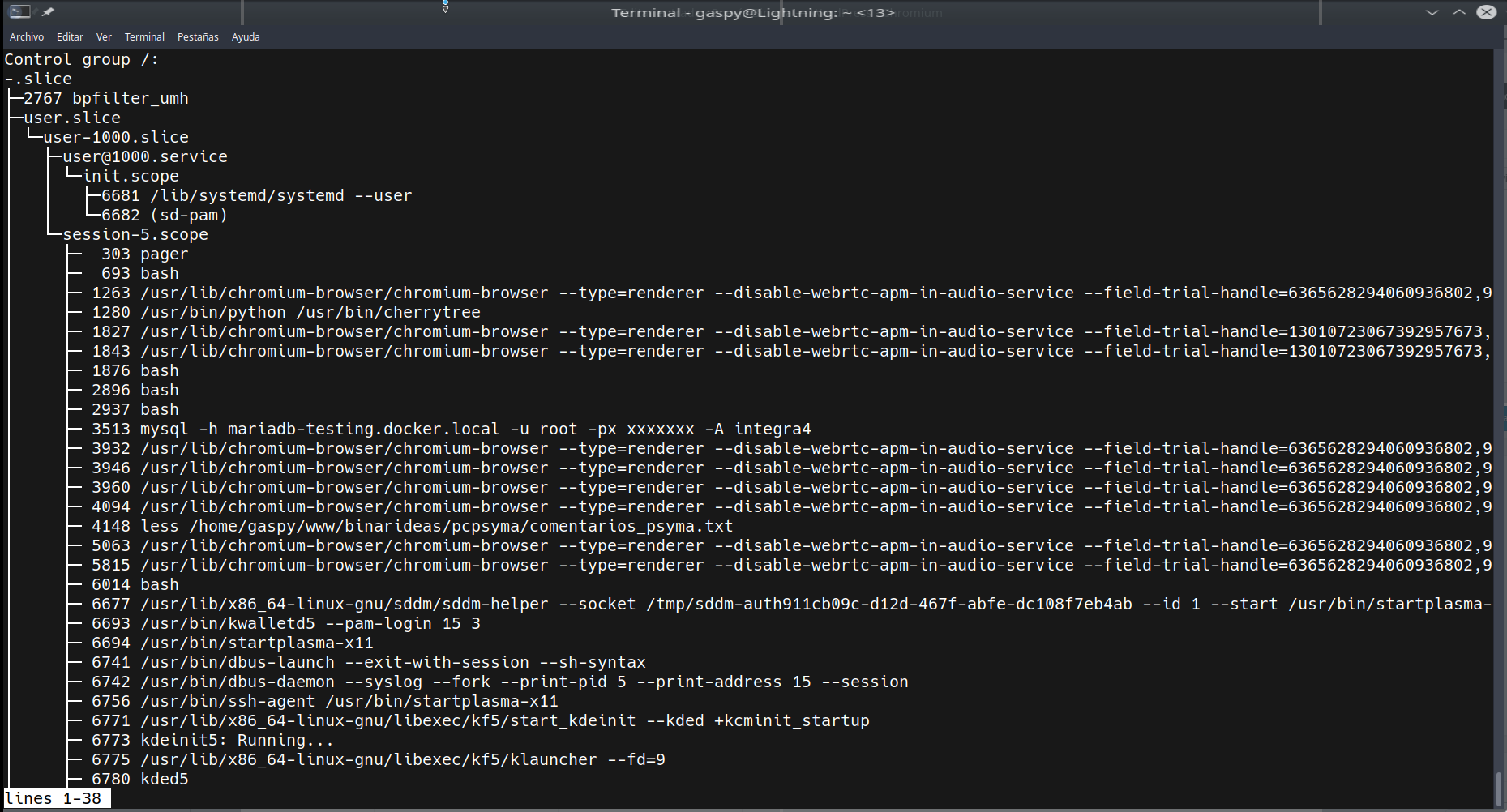
Nos devuelve algo como esto:
{kind=link}
Es un listado de todos los slices de manera jerárquica. Si observamos con atención podemos ver que hay un slice para usuarios (user.slice), para el sistema (system.slice) y a veces no aparece si no está en uso, otro para máquinas virtuales y linux containers (machine.slice). Eso nos permite establecer propiedades con systemctl set-property sobre esos slices. Por ejemplo:
Para que los usuarios no puedan exceder una cuota determinada de CPU. Aunque también vemos que cada usuario tiene su slice. Por ejemplo, user-1000.slice, por lo que podríamos decir:
Para que dicho usuario no pueda exceder esa cuota de CPU. Algo que puede ser de gran utilidad si administramos un servidor con varios usuarios y no queremos que alguno de ellos se pase.
Por ejemplo, también podríamos aplicar restricciones a Apache, PHP, MySQL, postfix, o demás servicios del modo habitual. O incluso a diferentes contenedores de docker (vía containerd.service). Además, si queremos ver qué cgroups están consumiendo CPU, memoria y demás, tenemos una utilidad systemd-cgtop, que nos muestra la información como el comando top, sencilla y actualizada cada segundo.
Más información
Si quieres más información sobre prioridad de procesos y cgroups:
- Control Groups (Red Hat)
- Limit CPU usage with cpulimit tool
- How to limit CPU usage of a process on Linux
- cpulimit / cputool
- RHEL7: How to get started with CGroups
Hay muchas más webs que hablan de ello, pero estas son algunas que he consultado para escribir este post.
Foto principal: Oleg Gospodarec
Foto pizza: Heather Gill
¿Necesitas un sysadmin?
Si te ha gustado el post y encuentras interesante lo que cuento en materia de sistemas. O si necesitas gestionar un servidor (o muchos), automatizar procesos o mejorar la calidad de los procesos actuales. No dudes en ponerte en contacto conmigo.